我正在编写一个程序,用于创建温度的可视化表示。有200个数据点布置在网格中,我使用插值方法填充这些点之间的像素。
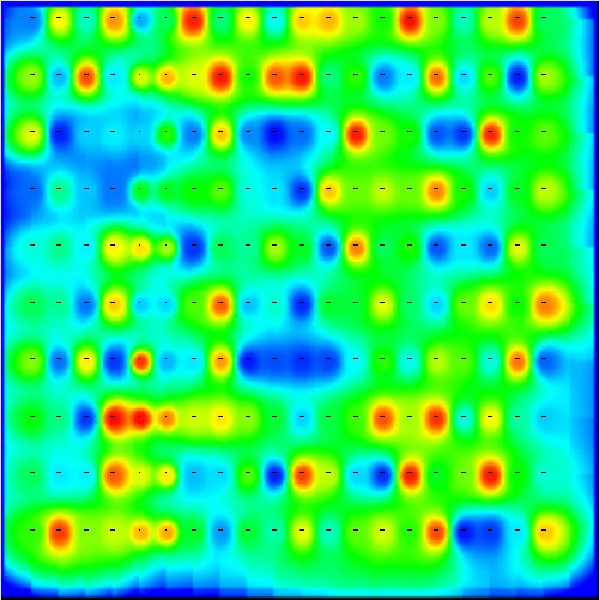
我编写了一个程序,使用反距离加权法(在本例中是修改后的Shepards方法)输出所需的数据,生成如下图所示的图像:
然后进行插值(随着温度的变化,这将重复进行)。这是时间成为关键因素的部分。
我的问题在于速度,对于一个200*200像素的图像,在我的电脑上运行第二部分代码大约需要30秒。有没有更快的方法来实现相同或类似的效果,或者我的代码存在明显的低效率?
我尝试了双线性和双三次插值,但对得到的图像并不满意。
我还限制了影响单个像素的数据点邻域,以试图加快速度,这确实有所帮助,但我认为我已经推到了极限,否则图像会出现明显的线条。
感谢您能提供的任何帮助。
我编写了一个程序,使用反距离加权法(在本例中是修改后的Shepards方法)输出所需的数据,生成如下图所示的图像:
剔除所有不相关的内容(如图像库内容),以下是创建此内容的代码:
首先计算每个点到每个管道的距离和总距离(因为这些是不变的)。在这一部分,我并不特别担心所花费的时间,因为它只需要执行一次,但我包含了代码,以便您可以看到值是如何存储的。
#set_tubes creates an array of tubes (which is the data I'm working on)
#each tube has an x position in pixels, a y position in pixels and a temperature
self.set_tubes()
self.dists = []
for x in range(1,BASE_WIDTH-1):
self.summed_dists.append([])
self.dists.append([])
for y in range(1,BASE_HEIGHT-1):
self.summed_dists[x-1].append([])
self.dists[x-1].append([])
self.summed_dists[x-1][y-1]=0
for row in range(10):
self.dists[x-1][y-1].append([])
for tube in range(20):
dist = np.sqrt((x-self.tubes[row][tube].xPos)**2+(y-self.tubes[row][tube].yPos)**2)+0.1
#The -3 in the next two lines is simply a weighting factor
self.dists[x-1][y-1][row].append(dist**(-3))
self.summed_dists[x-1][y-1] = self.summed_dists[x-1][y-1] + dist**(-3)
然后进行插值(随着温度的变化,这将重复进行)。这是时间成为关键因素的部分。
def other_proc_calc_temp(ret_queue, dists, tubes,summed_dists):
heat_values = list()
for x in range (BASE_WIDTH):
heat_values.append([])
for y in range(BASE_HEIGHT):
summed = 0
for row in range(10):
for tube in range(20):
dist = dists[x][y][row][tube]
temp = tubes[row][tube].temp
summed = summed + temp* dist/summed_dists[x-1][y-1]
heat_values[x].append(summed)
我的问题在于速度,对于一个200*200像素的图像,在我的电脑上运行第二部分代码大约需要30秒。有没有更快的方法来实现相同或类似的效果,或者我的代码存在明显的低效率?
我尝试了双线性和双三次插值,但对得到的图像并不满意。
我还限制了影响单个像素的数据点邻域,以试图加快速度,这确实有所帮助,但我认为我已经推到了极限,否则图像会出现明显的线条。
感谢您能提供的任何帮助。