终极问题
是否有一种通用且高效的分组操作方法,不依赖于pd.groupby函数?
输入
pd.DataFrame([[1, '2020-02-01', 'a'], [1, '2020-02-10', 'b'], [1, '2020-02-17', 'c'], [2, '2020-02-02', 'd'], [2, '2020-03-06', 'b'], [2, '2020-04-17', 'c']], columns=['id', 'begin_date', 'status'])`
id begin_date status
0 1 2020-02-01 a
1 1 2020-02-10 b
2 1 2020-02-17 c
3 2 2020-02-02 d
4 2 2020-03-06 b
期望输出
id status count uniquecount
0 1 a 1 1
1 1 b 1 1
2 1 c 1 1
3 2 b 1 1
4 2 c 1 1
问题
现在,有一种使用Pandas的Python简单方法可以做到这一点。
df = df.groupby(["id", "status"]).agg(count=("begin_date", "count"), uniquecount=("begin_date", lambda x: x.nunique())).reset_index()
# As commented, omitting the lambda and replacing it with "begin_date", "nunique" will be faster. Thanks!
对于较大的数据集,这个操作速度较慢,我猜测时间复杂度为O(n²)。
现有解决方案缺乏所需的普适性
经过一些谷歌搜索,StackOverflow 上有一些替代方案,使用 numpy、iterrows 或其他不同的方式。
Pandas 快速加权随机选择(Weighted Random Choice)
还有一个很好的答案:
这些解决方案通常旨在创建“count”或“uniquecount”,即聚合值,就像我例子中的一样。但是,很遗憾,它们总是只有一种聚合方式,并且没有多个 groupby 列。
另外,它们很可惜从未解释如何将它们合并到分组的 dataframe 中。
是否有一种方法可以使用 itertools(例如这个答案:更快的 Pandas 分组操作替代方法,或者更好的这个答案:Python Pandas 中的 Groupby:快速方法),不仅返回系列“count”,而且还要以分组形式返回整个 dataframe?
终极问题
是否有一种通用、高效的 groupby 操作方式,不依赖于 pd.groupby?
它可能看起来像这样:
from typing import List
def fastGroupby(df, groupbyColumns: List[str], aggregateColumns):
# numpy / iterrow magic
return df_grouped
df = fastGroupby(df, ["id", "status"], {'status': 'count',
'status': 'count'}
并返回期望的输出。
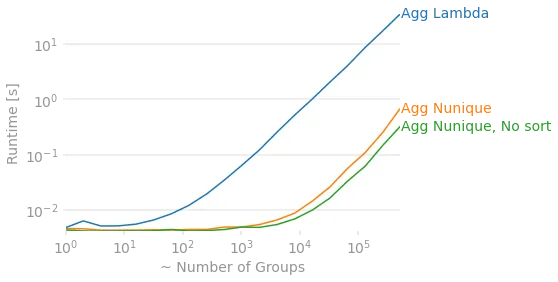
lambda函数正在拖垮你。它强制将其转换为组之间的缓慢循环。uniquecount=('status', 'nunique')可能会将速度提高数倍。然后,可以在groupby调用中进一步添加sort=False,这将使输出无序,但将显著提高多个组的速度。 - ALollz