我有三个ID列表。
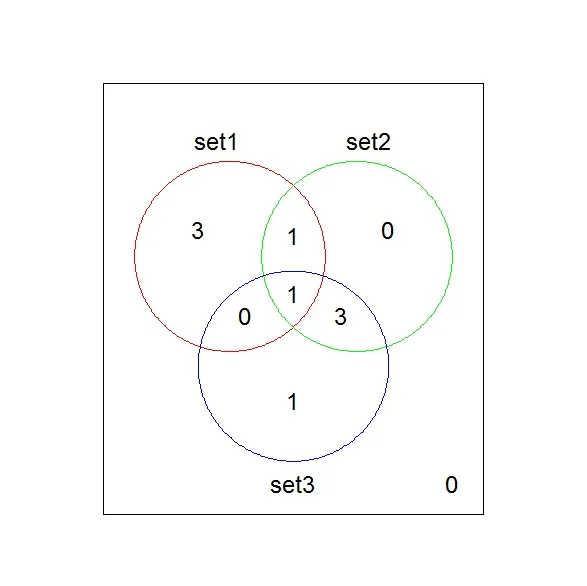
我想比较这3个列表,并绘制一个维恩图。在所得到的维恩图中,我想要显示交集中的不是数字而是ID。 我需要在R中完成这个任务,但我真的不知道该怎么做。 你能帮助我吗? 这是我的代码。它可以工作,但只显示数字,我想要在交叉点上显示“术语”。
set1 <- unique(goterm1)
set2 <- unique(goterm2)
set3 <- unique(goterm3)
require(limma)
Diagram <- function(set1, set2, set3, names)
{
stopifnot( length(names) == 3)
# Form universe as union of all three sets
universe <- sort( unique( c(set1, set2, set3) ) )
Counts <- matrix(0, nrow=length(universe), ncol=3)
colnames(Counts) <- names
for (i in 1:length(universe))
{
Counts[i,1] <- universe[i] %in% set1
Counts[i,2] <- universe[i] %in% set2
Counts[i,3] <- universe[i] %in% set3
}
vennDiagram( vennCounts(Counts) )}
Diagram(set1, set2, set3, c("ORG1", "ORG2", "ORG3"))
Venn

dput(goterm1) ; dput(goterm2);dput(goterm2)。 - IRTFM