我正在使用
最好使用一些模拟数据来解释这个问题(我的数据涉及方向和风速,我保留了相关名称)。
计数最少的速度类别(现在是“ [45,60)”)仅有3个计数,ggplot2会发出警告: position_stack需要具有不重叠的x间隔 图表将显示该类别数据分散在x轴上。如下图所示: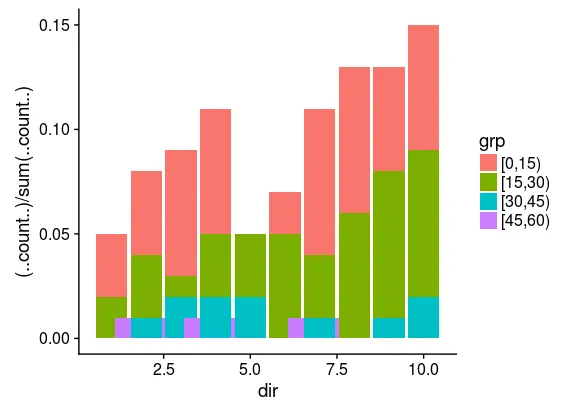 看起来,要使其正常工作,组的最小大小应为5。
看起来,要使其正常工作,组的最小大小应为5。
我想知道这是
谨此。
geom_bar中的..count..转换,并且当我的某些类别计数很少时,会收到警告position_stack需要不重叠的x间隔。最好使用一些模拟数据来解释这个问题(我的数据涉及方向和风速,我保留了相关名称)。
#make data
set.seed(12345)
FF=rweibull(100,1.7,1)*20 #mock speeds
FF[FF>60]=59
dir=sample.int(10,size=100,replace=TRUE) # mock directions
#group into speed classes
FFcut=cut(FF,breaks=seq(0,60,by=20),ordered_result=TRUE,right=FALSE,drop=FALSE)
# stuff into data frame & plot
df=data.frame(dir=dir,grp=FFcut)
ggplot(data=df,aes(x=dir,y=(..count..)/sum(..count..),fill=grp)) + geom_bar()
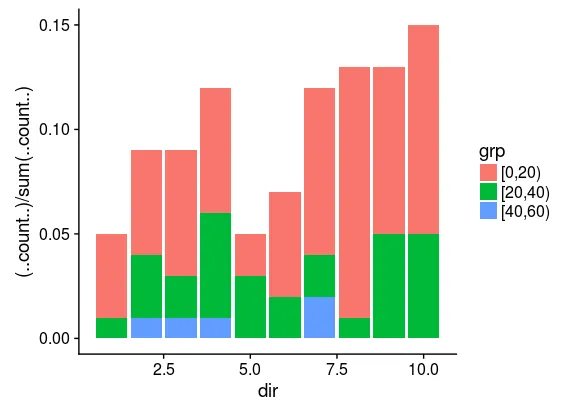
这个很好用,生成的图表显示了按照速度分组后方向频率。值得注意的是,最少计数的速度分类(此处为"[40,60)")将有5个计数。
然而,更多的速度分类会导致警告。例如,使用...
FFcut=cut(FF,breaks=seq(0,60,by=15),ordered_result=TRUE,right=FALSE,drop=FALSE)
计数最少的速度类别(现在是“ [45,60)”)仅有3个计数,ggplot2会发出警告: position_stack需要具有不重叠的x间隔 图表将显示该类别数据分散在x轴上。如下图所示:
看起来,要使其正常工作,组的最小大小应为5。我想知道这是
stat_bin(geom_bar使用的)中的特性还是错误,或者我是否过度滥用了geom_bar。同时,如果您有任何关于如何解决此问题的建议,我将不胜感激。谨此。
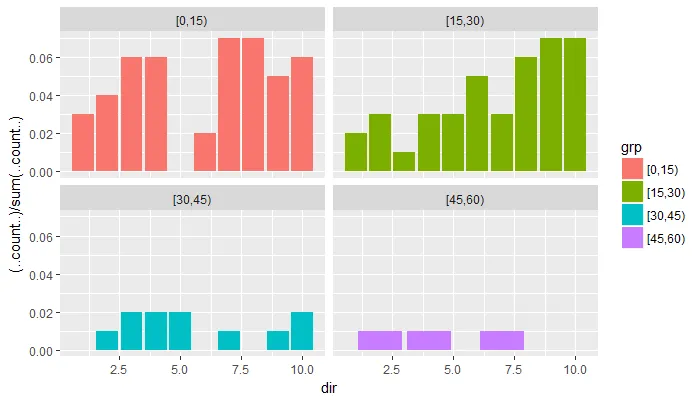
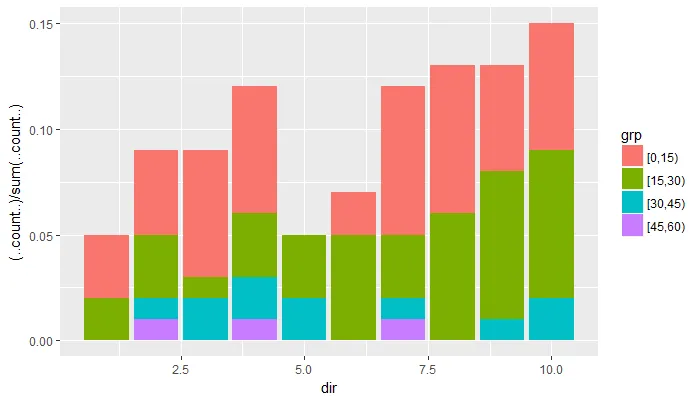

ggplot(data=df,aes(dir, fill=grp)) + geom_histogram(aes(y=(..count..)/sum(..count..)))- Roman