如何在程序中确保最大精度计算函数 f(x) 的导数?
我正在实现 牛顿-拉弗森法(Newton-Raphson method),它需要对函数求导。
如何在程序中确保最大精度计算函数 f(x) 的导数?
我正在实现 牛顿-拉弗森法(Newton-Raphson method),它需要对函数求导。
h = SQRT(DBL_EPSILON),其中DBL_EPSILON是机器精度下最小的双精度数e,满足1 + e != 1。 DBL_EPSILON约为10^-15,所以你可以使用h = 10^-7或10^-8。// #include "Eigen/Dense" // uncomment this, and check the result
#include <functional>
#include <iostream>
#include <limits>
#include <cmath>
typedef std::function<double(double)> RealFunc;
typedef std::function<double(std::function<double(double)>, double)> RealFuncDerivative;
double FibonacciFunc(double x) {
return pow(x, 3) + 2.0 * pow(x, 2) + 10.0 * x - 20.0;
}
double derivative(RealFunc f, double x) {
double h = sqrt(std::numeric_limits<double>::epsilon());
return (f(x + h) - f(x - h)) / (2.0 * h);
}
double NewtonsMethod(RealFunc f, RealFuncDerivative d, double x0, double precision) {
double x = x0;
for (size_t i = 0;; i++) {
x = x - (f(x) / d(f, x));
if (abs(f(x)) < precision) {
return x;
}
}
}
int main() {
RealFunc f{FibonacciFunc};
RealFuncDerivative d{derivative};
std::cout << NewtonsMethod(f, d, 1.0, 10e-4) << "\n";
}
牛顿-拉弗森法(Newton_Raphson)假定您可以拥有两个函数 f(x) 及其导数 f'(x)。如果您没有可用的导数函数并且必须从原始函数估计导数,则应使用另一种根查找算法。
维基百科根查找 给出了几个建议,就像任何数值分析文本一样。
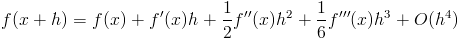
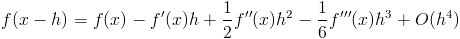
1)第一种情况:
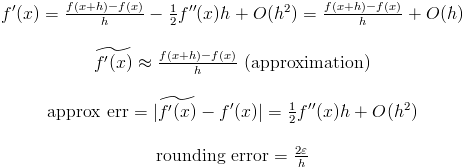
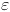 — 相对误差约为双精度 2^{-16} 和单精度 2^{-7}。
— 相对误差约为双精度 2^{-16} 和单精度 2^{-7}。
我们可以计算总误差:
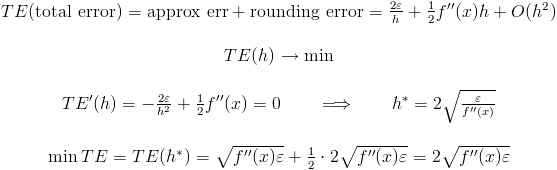
假设您正在使用双浮点运算。因此,h 的最佳值是 2sqrt(DBL_EPSILON/f''(x))。你不知道 f''(x)。但你必须估计这个值。例如,如果 f''(x) 约为 1,则 h 的最佳值为 2^{-7},但如果 f''(x) 约为 10^6,则 h 的最佳值为 2^{-10}!
2)第二种情况:

请注意,第二个近似误差比第一个近似误差更快地趋近于零。但如果 f'''(x) 很大,则第一种选项更可取:
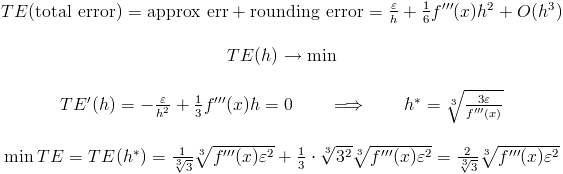
请注意,在第一种情况下,h 与 e 成正比,而在第二种情况下,h 与 e^{1/3} 成正比。对于双精度浮点运算,e^{1/3} 约为 2^{-5} 或 2^{-6}。(我假设 f'''(x) 约为 1)。
哪种方法更好? 如果您不知道f''(x)和f'''(x),或者您无法估计这些值,则未知。据信第二个选项更可取。但是,如果您知道f'''(x)非常大,请使用第一个选项。
h的最佳值是多少? 假设f''(x)和f'''(x)约为1。并且假设我们使用双精度浮点运算。那么在第一种情况下,h约为2^{-8},在第二种情况下,h约为2^{-5}。如果您知道f''(x)或f'''(x),请更正这些值。
abs(f(x))*eps 的倍数,其中多重性与评估 f(x) 中的浮点运算次数有关。因此,对于中心差分,h~cbrt(abs(f(x)/f'''(x))*eps)。 - Lutz Lehmannfprime(x) = (f(x+dx) - f(x-dx)) / (2*dx)
对于一些小的 DX。
当你选择h的值时,考虑John Cook的建议是很重要的,但通常不要使用中心差分来近似导数。主要原因是如果你使用前向差分,它会多消耗一个函数计算。
f'(x) = (f(x+h) - f(x))/h
由于您已经需要计算牛顿法中的f(x),所以您将免费获取f(x)的值。当您有一个标量方程时,这并不是什么大问题,但如果x是一个向量,则f'(x)是一个矩阵(雅可比矩阵),并且您需要进行n个额外的函数评估,使用居中差分方法来近似它。
除了John D. Cook上面的回答之外,重要的是不仅要考虑浮点精度,还要考虑函数f(x)的鲁棒性。例如,在金融领域中,f(x)实际上是蒙特卡罗模拟,f(x)的值具有一定的噪声。在这些情况下,使用非常小的步长可能会严重降低导数的准确性。