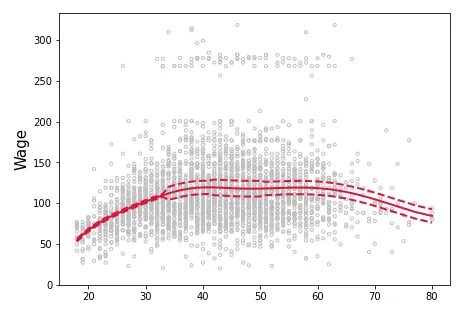
我想在我所制作的数据三次样条曲线图上展示置信区间,但是我不知道应该如何做。从理论上来说,当我们接近边缘时,置信区间应该与拟合线分离,但我所想到的唯一解决方案是这个有缺陷的添加方式,它并没有显示出正确的置信区间。
以下是代码:
以下是代码:
import pandas as pd
from patsy import dmatrix
import statsmodels.api as sm
import matplotlib.pyplot as plt
import numpy as np
plt.figure(figsize=(7,5))
df = pd.read_csv('http://web.stanford.edu/~oleg2/hse/wage/wage.csv').sort_values(by=['age'])
ind_df = df[['wage', 'age']].copy()
def get_bse(bse, k, m, ma, x):
prev, ans = m, []
k.append(ma+1)
for i, k_ in enumerate(k):
ans += [bse[i]]*np.sum( ((x >= prev) & (x < k_)) ); prev = k_
return np.array(ans)
plt.scatter(df.age, df.wage, color='none', edgecolor='silver', s=10)
plt.xlabel('Age', fontsize=15)
plt.ylabel('Wage', fontsize=15)
plt.ylim((0,333))
d = 4
knots = [df.age.quantile(0.25), df.age.quantile(0.5), df.age.quantile(0.75)]
my_spline_transformation = f"bs(train, knots={knots}, degree={d}, include_intercept=True)"
transformed = dmatrix( my_spline_transformation, {"train": df.age}, return_type='dataframe' )
ft = sm.GLS(df.wage, transformed).fit()
lft = sm.Logit( (df.age > 250), transformed )
y_grid1 = lft.predict(transformed.transpose())
y_grid = ft.predict(transformed)
plt.plot(df.age, y_grid, color='crimson', linewidth=2)
plt.plot(df.age, y_grid + get_bse(ft.bse, knots, df.age.min(), df.age.max(), df.age), color='crimson', linewidth=2, linestyle='--')
plt.plot(df.age, y_grid - get_bse(ft.bse, knots, df.age.min(), df.age.max(), df.age), color='crimson', linewidth=2, linestyle='--')
plt.show()