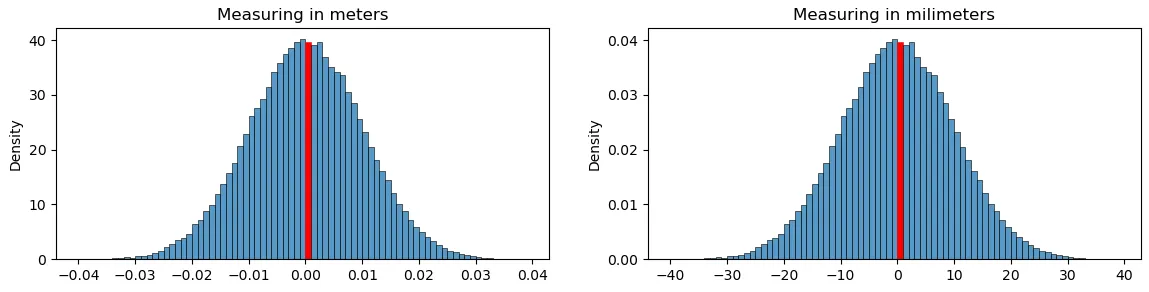
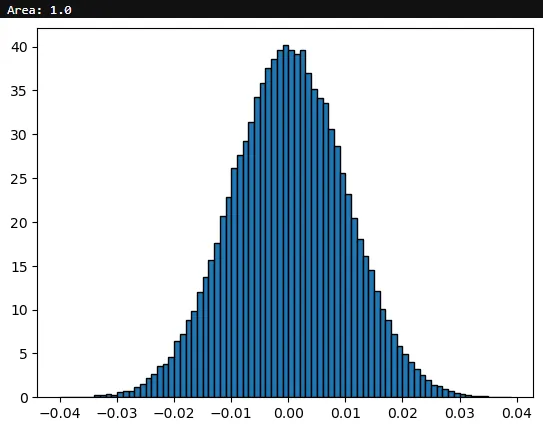
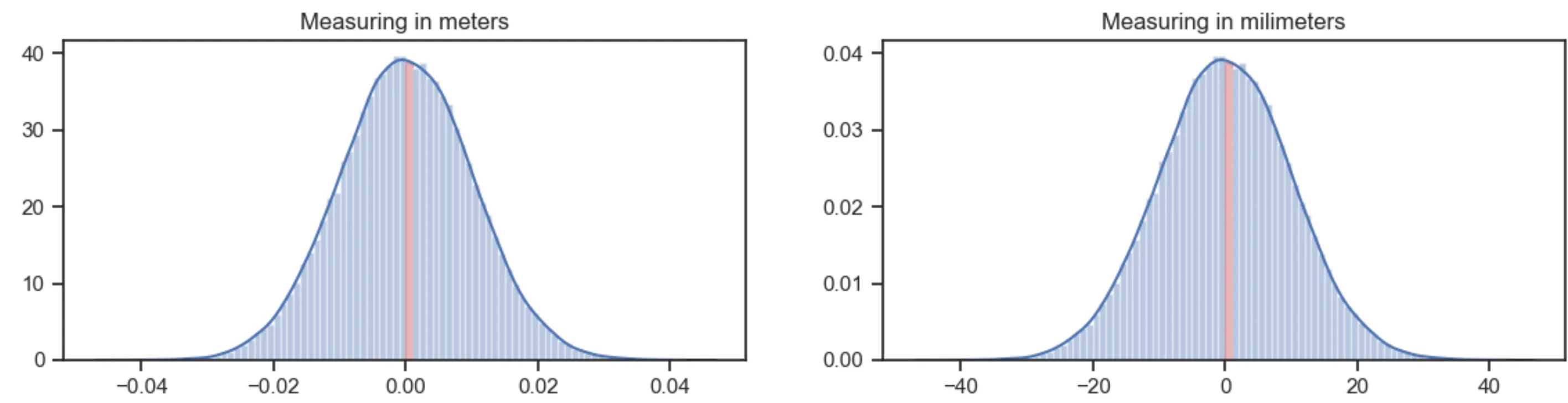
有时候,当我使用seaborn的displot函数创建直方图时,如果norm_hist参数设置为True,则y轴值将小于1,这符合概率密度函数(PDF)的预期。但有时候y轴的值会大于1。
例如,如果我运行以下代码:
为了让数据总和为1,无论norm_hist参数是否为True,y轴仍将显示比1大得多的值(例如30)。当y轴具有如此大的范围时,我可以给出什么解释?
我认为发生的情况是我的数据集紧密地聚集在零周围,因此为了使数据集在核密度估计下的面积等于1,直方图的高度必须大于1...但由于概率不能超过1,那么结果意味着什么?
另外,我如何使这些函数在y轴上显示概率?
例如,如果我运行以下代码:
sns.set();
x = np.random.randn(10000)
ax = sns.distplot(x)
如果数据是正常分布的,那么直方图上的y轴应该从0.0到0.4,但如果数据不是正常分布,则即使norm_hist = True,y轴也可能高达30。
关于直方图函数的规范化参数,例如sns.distplot中的norm_hist,我缺少什么?即使我通过创建一个新变量自己对数据进行归一化如下:
new_var = data/sum(data)
为了让数据总和为1,无论norm_hist参数是否为True,y轴仍将显示比1大得多的值(例如30)。当y轴具有如此大的范围时,我可以给出什么解释?
我认为发生的情况是我的数据集紧密地聚集在零周围,因此为了使数据集在核密度估计下的面积等于1,直方图的高度必须大于1...但由于概率不能超过1,那么结果意味着什么?
另外,我如何使这些函数在y轴上显示概率?