我已成功安装并配置好了Tesseract,可以将图片转换为文字...
text = pytesseract.image_to_string(Image.open(image))
然而,我需要获取每行的置信度值。使用pytesseract无法找到实现此操作的方法。有人知道如何做吗?
我知道可以使用PyTessBaseAPI实现此操作,但是我无法使用它,花了几个小时尝试设置但没有成功,因此我需要一种使用pytesseract实现此操作的方法。
我已成功安装并配置好了Tesseract,可以将图片转换为文字...
text = pytesseract.image_to_string(Image.open(image))
然而,我需要获取每行的置信度值。使用pytesseract无法找到实现此操作的方法。有人知道如何做吗?
我知道可以使用PyTessBaseAPI实现此操作,但是我无法使用它,花了几个小时尝试设置但没有成功,因此我需要一种使用pytesseract实现此操作的方法。
经过大量搜索,我已经找到了一种方法。不要使用image_to_string,而是应该使用image_to_data。然而,这将为您提供每个单词的统计信息,而不是每行...
text = pytesseract.image_to_data(Image.open(file_image), output_type='data.frame')
pandas 按照 block_num 分组,因为每一行都是使用 OCR 分组成块的,我还删除了所有信心值为 (-1) 的行...text = text[text.conf != -1]
lines = text.groupby('block_num')['text'].apply(list)
使用相同的逻辑,您还可以通过计算同一块中所有单词的平均置信度来计算每行的置信度...
conf = text.groupby(['block_num'])['conf'].mean()
@Srikar Appalaraju是正确的。看下面这张图片的例子:

text = pytesseract.image_to_data(gray, output_type='data.frame')
text = text[text.conf != -1]
text.head()
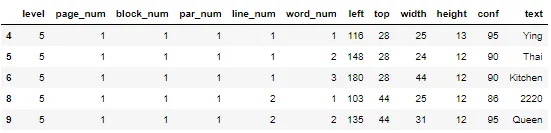
block_num,因此如果我们使用该列进行分组,则这 5 个单词(文本)将被分组在一起。但这不是我们想要的,我们只想将属于第一行的前三个单词分组,为了以通用的方式正确执行此操作(对于足够大的图像),我们需要同时按 page_num、block_num、par_num 和 line_num 进行分组,以计算第一行的置信度,如下面的代码片段所示:lines = text.groupby(['page_num', 'block_num', 'par_num', 'line_num'])['text'] \
.apply(lambda x: ' '.join(list(x))).tolist()
confs = text.groupby(['page_num', 'block_num', 'par_num', 'line_num'])['conf'].mean().tolist()
line_conf = []
for i in range(len(lines)):
if lines[i].strip():
line_conf.append((lines[i], round(confs[i],3)))
需要以下期望输出:
[('Ying Thai Kitchen', 91.667),
('2220 Queen Anne AVE N', 88.2),
('Seattle WA 98109', 90.333),
('« (206) 285-8424 Fax. (206) 285-8427', 83.167),
('‘uw .yingthaikitchen.com', 40.0),
('Welcome to Ying Thai Kitchen Restaurant,', 85.333),
('Order#:17 Table 2', 94.0),
('Date: 7/4/2013 7:28 PM', 86.25),
('Server: Jack (1.4)', 83.0),
('44 Ginger Lover $9.50', 89.0),
('[Pork] [24#]', 43.0),
('Brown Rice $2.00', 95.333),
('Total 2 iten(s) $11.50', 89.5),
('Sales Tax $1.09', 95.667),
('Grand Total $12.59', 95.0),
('Tip Guide', 95.0),
('TEK=$1.89, 18%=62.27, 20%=82.52', 6.667),
('Thank you very much,', 90.75),
('Cone back again', 92.667)]
目前被接受的答案并不完全正确。使用 pytesseract 获取每个 line 的正确方法是:
text.groupby(['block_num','par_num','line_num'])['text'].apply(list)
我们需要根据这个答案来做:有人知道pytesseract的image_to_data、image_to_osd方法输出的含义吗?
但是以上4列都是相互关联的。如果该项来自新行,则单词编号将从0重新开始计数,而不是从上一行的最后一个单词编号继续。行号、段落编号、块编号也是如此。