我正在使用Python 2.7,Pytesseract-0.1.7和Tesseract-ocr 3.05.01在Windows机器上。
我尝试提取韩语和俄语的文本,并且我相信我已经成功提取了。
现在我需要将其与从图像中提取的字符串进行比较。
但我无法对这些字符串进行比较,并得到正确的结果,它只是显示不匹配。
这是我的代码:
# -*- coding: utf-8 -*-
from PIL import Image
import pytesseract
import argparse
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--input", required=True, help="path to the image")
args = vars(ap.parse_args())
img = Image.open(args["input"])
img.load()
text = pytesseract.image_to_string(img)
print(text)
text = text.encode('ascii')
print(text)
i = 'Сред. Скорость'
print i
if ( text == i):
print "Match"
else :
print "Not Match"
附上了用于提取文本的图像。
现在我需要一种匹配它的方法。而且我还需要知道从pytesseract提取的字符串是否为Unicode,如果有将其转换为Unicode的方法(就像我们在Wordpad中将字符转换成Unicode的选项一样)。
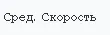
coding行下面)包含from __future__ import print_function,那么这将帮助您一致地使用print函数。现在,print(text)是一个print语句,后跟具有非功能括号的text。 - Anthon