我正在使用pytesseract从图像中提取数据。这个模块有image_to_data和image_to_osd方法。这两种方法提供了很多信息(TextLineOrder,WritingDirection,ScriptDetection,Orientation等)作为输出。
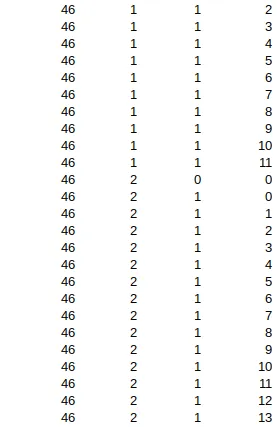
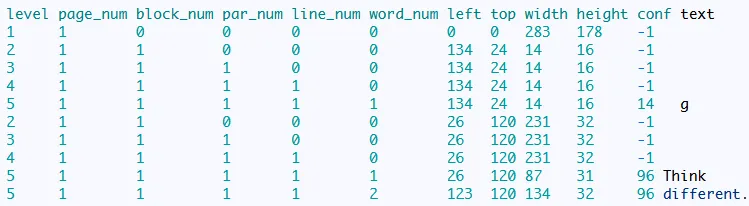
下面的图片是image_to_data方法的输出。这些列(level, block_num, par_num, line_num, word_num)的值代表什么意思?

image_to_osd的输出如下。每个术语都代表什么含义?
页码:0 度数方向:0 旋转:0 方向置信度:16.47 脚本:拉丁文 脚本置信度:4.00
我查阅了文档,但没有找到任何有关这些参数的信息。
{kind=link}
{kind=link}