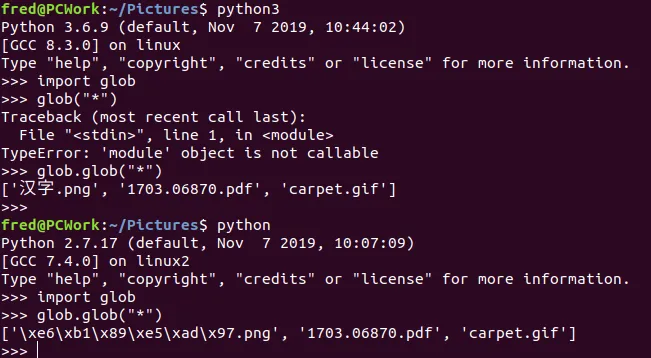
我有一个图片目录,每个图片的名称中都带有一个汉字。我想列出所有这些图片,遍历列表,读取并显示每张图片。
图片路径类似于 https://github.com/sirius-ai/LPRNet_Pytorch/tree/master/data/test 在 Python3.6.9 中,使用
图片路径类似于 https://github.com/sirius-ai/LPRNet_Pytorch/tree/master/data/test 在 Python3.6.9 中,使用
glob 获取到的图片名称如下:

当我使用cv2.imread读取它们时,会导致分段错误。
我该如何解决这个问题?