这个问题让我着迷了整整一周,所以在周末我深入研究并找到了一个解决方案,我称之为
MultiFontParagraph。它是一个普通的
Paragraph,但有一个很大的区别,你可以精确地设置字体回退顺序。
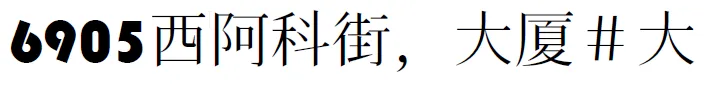
例如,我从互联网上随机获取了这段日文文本,使用了以下字体回退
"Bauhaus","Arial","HanaMinA"。它检查第一个字体是否具有该字符的字形,如果是,则使用它,否则就会回退到下一个字体。目前,该代码并不是真正有效的,因为它在每个字符周围放置标签,但这很容易修复,但出于清晰起见,我没有在此处进行修复。
使用以下代码,我创建了上面的示例:
foreign_string = u'6905\u897f\u963f\u79d1\u8857\uff0c\u5927\u53a6\uff03\u5927'
P = MultiFontParagraph(foreign_string, styles["Normal"],
[ ("Bauhaus", "C:\Windows\Fonts\\BAUHS93.TTF"),
("Arial", "C:\Windows\Fonts\\arial.ttf"),
("HanaMinA", 'C:\Windows\Fonts\HanaMinA.ttf')])
MultiFontParagraph (git) 的源代码如下:
from reportlab.pdfbase import pdfmetrics
from reportlab.pdfbase.ttfonts import TTFont
from reportlab.platypus import Paragraph
class MultiFontParagraph(Paragraph):
def __init__(self, text, style, fonts_locations):
font_list = []
for font_name, font_location in fonts_locations:
font = TTFont(font_name, font_location)
font_widths = font.face.charWidths
pdfmetrics.registerFont(font)
font_list.append((font_name, font_widths))
new_text = u''
for char in text:
for font_name, font_widths in font_list:
if ord(char) in font_widths:
new_text += u'<font name="{}">{}</font>'.format(font_name, char)
break
Paragraph.__init__(self, new_text, style)