我有以下代码,但因为无法从磁盘读取文件而失败。图像始终为None。
# -*- coding: utf-8 -*-
import cv2
import numpy
bgrImage = cv2.imread(u'D:\\ö\\handschuh.jpg')
注意:我的文件已经保存为带有BOM的UTF-8格式。我用Notepad++进行了验证。
在Process Monitor中,我发现Python正在从错误的路径访问该文件:
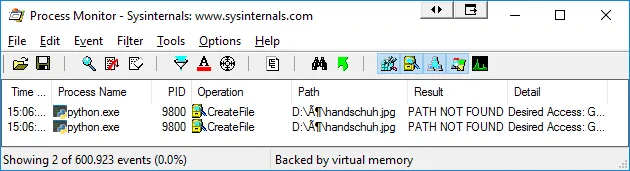
我已经阅读了以下内容:
- 使用具有Unicode文件名的open(),这是关于
open()函数而与OpenCV无关。 - 如何使用Python读取图像文件,但这与Unicode问题无关。
os.path.isfile(myPath)来检查文件是否存在,然后用cv2.imread打开它,但它总是显示为“None”对象!非常愤怒。你的解决方案解决了我的问题。谢谢。 - Endydcv2.imdecode(np.fromfile(u'D:\\ö\\handschuh.jpg', np.uint8), cv2.IMREAD_UNCHANGED)即可。 - jdhao