我的问题是为什么WHERE运算符的速度不如预期?
假设我有7个标记为Consumer的节点。以下是一些示例数据...
MERGE (c:Consumer {mobileNumber: "000000000000"})
MERGE (:Consumer {mobileNumber: "111111111111"})
MERGE (:Consumer {mobileNumber: "222222222222"})
MERGE (:Consumer {mobileNumber: "333333333333"})
MERGE (:Consumer {mobileNumber: "444444444444"})
MERGE (:Consumer {mobileNumber: "555555555555"})
MERGE (:Consumer {mobileNumber: "666666666666"})
WITH c
MATCH (c1:Consumer) WHERE c1.mobileNumber <> "000000000000"
MERGE (c)-[:HAS_CONTACT]->(c1)
在:Consumer(mobileNumber:{"000000000000"})和其他6个节点之间存在一个HAS_CONTACT关系。此外,mobileNumber字段上还有一个unique index约束。现在当我尝试执行以下查询时:
PROFILE MATCH (n:Consumer{mobileNumber : "000000000000"}),
(m:Consumer{mobileNumber : "111111111111"})
WITH n,m
MATCH path = SHORTESTPATH((n)-[contacts:HAS_CONTACT]-(m))
RETURN contacts;
搜索节点基于唯一索引,它的工作正常。以下是它的结果:
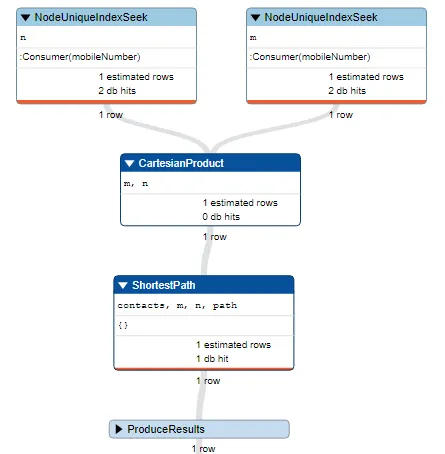
现在使用WHERE子句改变上述查询:
PROFILE MATCH (n:Consumer{mobileNumber : "000000000000"}),
(m:Consumer) WHERE m.mobileNumber
IN (["111111111111"])
WITH n,m
MATCH path = SHORTESTPATH((n)-[contacts:HAS_CONTACT]-(m))
RETURN contacts;
查询结果:
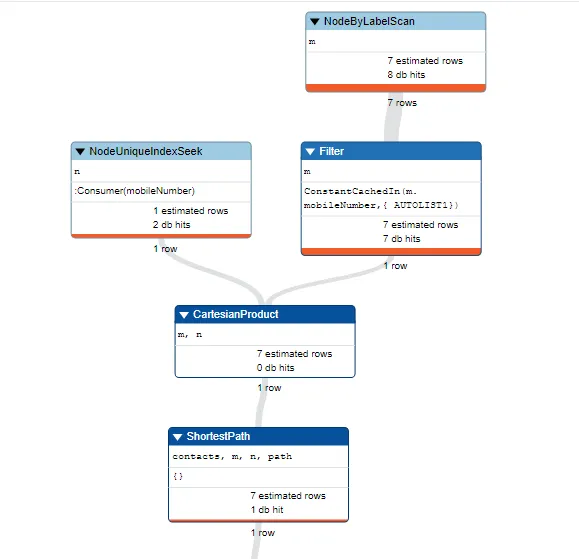
虽然上面的查询正常工作并给出与旧查询相同的结果。但是对于使用WHERE子句的endNode,它不使用任何索引。 它首先搜索所有现有节点,然后使用WHERE子句过滤结果,如果具有相同标签的数十万个节点,则这可能非常昂贵。
所以我的问题是:
- 为什么使用
WHERE子句时它不使用索引? - 引用多个节点的最佳方法是什么,以减少数据库访问次数?
- 在期望索引搜索的情况下,我可以使用
IN运算符吗?
:Consumer(mobileNumber)上创建了一个约束。运行它后,我收到了你预期的结果。 - Dave Bennett