我希望在Neo4j上写一个Cypher查询并运行它。
查询如下:
给定一些起始顶点,遍历边并找到所有与任何起始顶点相连的顶点。
(start)-[*]->(v)
针对每条被遍历的边E
if startVertex(E).someproperty != endVertex(E).someproperty, output E.
该图可能包含循环。
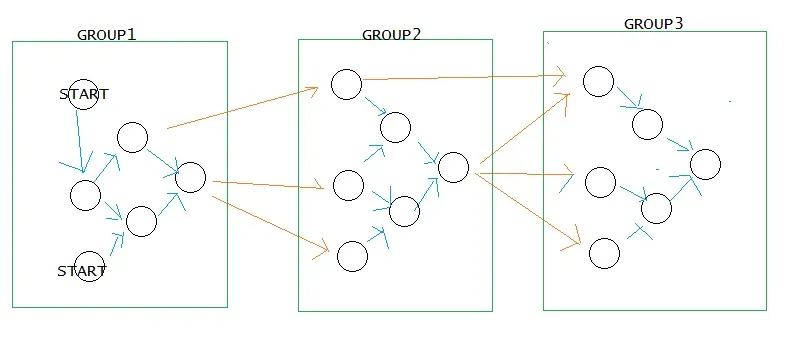
例如,在上面的图中,顶点按“group”属性分组。查询应返回7行,代表图中7个橙色边缘。
如果我自己编写算法,它将是一个简单的深度/广度优先搜索,并且对于访问的每条边,如果过滤条件为真,则输出此边缘。复杂度为O(V+E)。
但是,由于Cypher语言与之很不同,因此我无法用Cypher表达这个算法。
然后我写了这个查询:
查找所有可达的顶点
(start)-[*]->(v), reachable = start + v.
查找从任何可访问的起始点开始的所有边。如果一条边以任何可达顶点结束并通过筛选器,则输出它。
match (reachable)-[]->(n) where n in reachable and reachable.someprop != n.someprop
因此,Cypher代码如下所示:
MATCH (n:Col {schema:"${DWMDATA}",table:"CHK_P_T80_ASSET_ACCT_AMT_DD"})
WITH n MATCH (n:Col)-[*]->(m:Col)
WITH collect(distinct n) + collect(distinct m) AS c1
UNWIND c1 AS rn
MATCH (rn:Col)-[]->(xn:Col) WHERE rn.schema<>xn.schema and xn in c1
RETURN rn,xn
我认为这个查询的性能并不如我所想。这是在:Col(schema)上建立了索引。
我正在我的Windows笔记本电脑上运行来自DockerHub的neo4j 2.3.0 docker镜像。实际上,它在我的笔记本电脑上的Linux虚拟机上运行。
我的示例数据集是一个包含0.1M个顶点和0.5M个边缘的小数据集。对于一些起始节点,执行此查询需要60秒或更长时间。有什么优化或重写查询的建议吗?谢谢。
以下代码块是我想要的逻辑:
VertexQueue1 = (starting vertexes);
VisitedVertexSet = (empty);
EdgeSet1 = (empty);
While (VertexSet1 is not empty)
{
Vertex0 = VertexQueue1.pop();
VisitedVertexSet.add(Vertex0);
foreach (Edge0 starting from Vertex0)
{
Vertex1 = endingVertex(Edge0);
if (Vertex1.schema <> Vertex0.schema)
{
EdgeSet1.put(Edge0);
}
if (VisitedVertexSet.notContains(Vertex1)
and VertexQueue1.notContains(Vertex1))
{
VertexQueue1.push(Vertex1);
}
}
}
return EdgeSet1;
编辑:
档案结果显示,展开所有路径的成本很高。从行号来看,似乎Cypher exec引擎返回了所有路径,但我只想要不同的边缘列表。
左边:
match (start:Col {table:"F_XXY_DSMK_ITRPNL_IDX_STAT_W"})
,(start)-[*0..]->(prev:Col)-->(node:Col)
where prev.schema<>node.schema
return distinct prev,node
正确的一种:
MATCH (n:Col {schema:"${DWMDATA}",table:"CHK_P_T80_ASSET_ACCT_AMT_DD"})
WITH n MATCH (n:Col)-[*]->(m:Col)
WITH collect(distinct n) + collect(distinct m) AS c1
UNWIND c1 AS rn
MATCH (rn:Col)-[]->(xn:Col) WHERE rn.schema<>xn.schema and xn in c1
RETURN rn,xn
