我可以帮您翻译成中文。以下是需要翻译的内容:
另一个问题是关于Filter操作符:为什么它需要12个数据库访问,尽管所有节点/关系已经被检索到了?为什么这个操作需要12个数据库调用才能得到6行结果?
我正在查询的是完整的图形: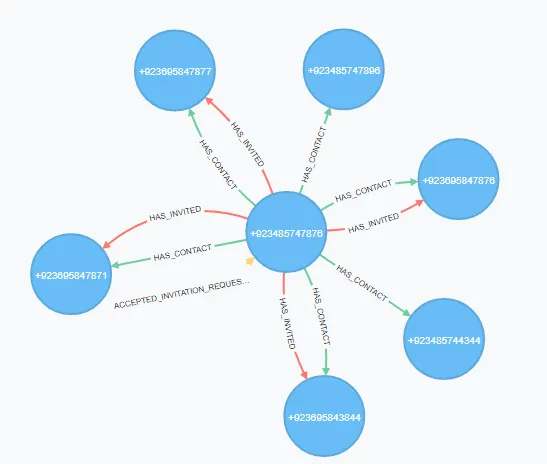 此外,我已经测试了同一查询的不同版本,但返回的是相同的查询概要结果。
此外,我已经测试了同一查询的不同版本,但返回的是相同的查询概要结果。
我对Neo4j的查询分析有一些问题。 考虑以下简单的Cypher查询:
PROFILE
MATCH (n:Consumer {mobileNumber: "yyyyyyyyy"}),
(m:Consumer {mobileNumber: "xxxxxxxxxxx"})
WITH n,m
MATCH (n)-[r:HAS_CONTACT]->(m)
RETURN n,m,r;
输出结果为:
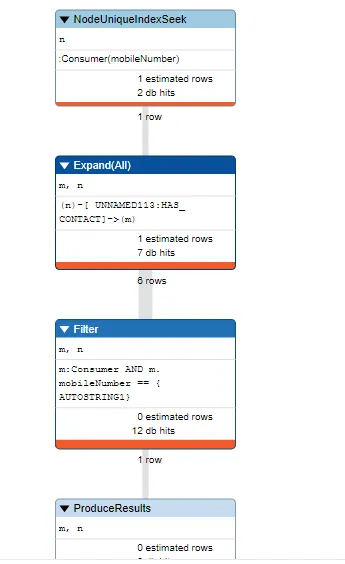
在上面的查询中(在我的情况下),首先它应该找到StartNode和EndNode,然后再查找任何关系。但不幸的是,它只找到了StartNode,然后展开了所有连接的:HAS_CONTACT关系,这导致没有使用"Expand Into"操作符。为什么会这样呢?两个节点之间只有一个:HAS_CONTACT关系。在:Consumer{mobileNumber}上有一个唯一索引约束。为什么上述查询会展开所有7个关系?3.7.2.2. Expand Into
When both the start and end node have already been found, expand-into is used to find all connecting relationships between the two nodes.
Query.
MATCH (p:Person { name: 'me' })-[:FRIENDS_WITH]->(fof)-->(p) RETURN > fof
另一个问题是关于Filter操作符:为什么它需要12个数据库访问,尽管所有节点/关系已经被检索到了?为什么这个操作需要12个数据库调用才能得到6行结果?
我正在查询的是完整的图形:
此外,我已经测试了同一查询的不同版本,但返回的是相同的查询概要结果。
1
PROFILE
MATCH (n:Consumer{mobileNumber: "yyyyyyyyy"})
MATCH (m:Consumer{mobileNumber: "xxxxxxxxxxx"})
WITH n,m
MATCH (n)-[r:HAS_CONTACT]->(m)
RETURN n,m,r;
2
PROFILE
MATCH (n:Consumer{mobileNumber: "yyyyyyyyy"}), (m:Consumer{mobileNumber: "xxxxxxxxxxx"})
WITH n,m
MATCH (n)-[r:HAS_CONTACT]->(m)
RETURN n,m,r;
3
PROFILE
MATCH (n:Consumer{mobileNumber: "yyyyyyyyy"})
WITH n
MATCH (n)-[r:HAS_CONTACT]->(m:Consumer{mobileNumber: "xxxxxxxxxxx"})
RETURN n,m,r;
MATCH子句,而不是一个带有逗号的子句? - Dom Weldon