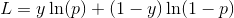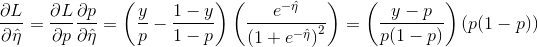我希望了解在xgboost示例脚本中,logloss函数的梯度和海森矩阵是如何计算的。我已经简化了函数以使用numpy数组,并生成了
这是一个简化的示例:
对数损失函数是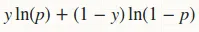 的总和,其中
的总和,其中 。
。
然后,对于p,梯度为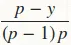 ,但在代码中为
,但在代码中为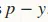 。
。
同样,对于p,二阶导数为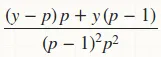 ,但在代码中为
,但在代码中为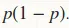 。
。
这些方程式怎么相等?
y_hat和y_true,它们是脚本中使用的值的样本。这是一个简化的示例:
import numpy as np
def loglikelihoodloss(y_hat, y_true):
prob = 1.0 / (1.0 + np.exp(-y_hat))
grad = prob - y_true
hess = prob * (1.0 - prob)
return grad, hess
y_hat = np.array([1.80087972, -1.82414818, -1.82414818, 1.80087972, -2.08465433,
-1.82414818, -1.82414818, 1.80087972, -1.82414818, -1.82414818])
y_true = np.array([1., 0., 0., 1., 0., 0., 0., 1., 0., 0.])
loglikelihoodloss(y_hat, y_true)
对数损失函数是
的总和,其中。然后,对于p,梯度为
,但在代码中为。同样,对于p,二阶导数为
,但在代码中为。这些方程式怎么相等?