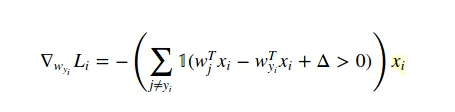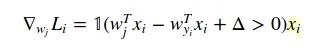我正在尝试实现SVM损失函数及其梯度。我找到了一些示例项目,它们实现了这两个功能,但我无法弄清楚在计算梯度时如何使用损失函数。
以下是损失函数的公式: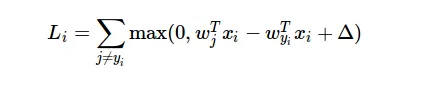 我不明白的是,如何在计算梯度时使用损失函数的结果?
我不明白的是,如何在计算梯度时使用损失函数的结果?
该示例项目的梯度计算方法如下:
以下是损失函数的公式:
我不明白的是,如何在计算梯度时使用损失函数的结果?该示例项目的梯度计算方法如下:
for i in xrange(num_train):
scores = X[i].dot(W)
correct_class_score = scores[y[i]]
for j in xrange(num_classes):
if j == y[i]:
continue
margin = scores[j] - correct_class_score + 1 # note delta = 1
if margin > 0:
loss += margin
dW[:,j] += X[i]
dW[:,y[i]] -= X[i]
dW 是梯度结果。X 是训练数据的数组。 但我不理解损失函数的导数是如何导致这段代码的。