在 C/C++ 程序中,有没有标准和/或可移植的方法来表示最小的负值(例如使用负无穷)?
float.h 中的 DBL_MIN 是最小的正数。
在 C/C++ 程序中,有没有标准和/或可移植的方法来表示最小的负值(例如使用负无穷)?
float.h 中的 DBL_MIN 是最小的正数。
-DBL_MAX 在 ANSI C 中, 它在 float.h 中被定义。
-DBL_MAX必须能够被精确表示,因此如果FP硬件无法实现该要求,则实现只需绕过该要求即可。请参阅C99中* 5.2.4.2.2浮点类型的特征<float.h> p2 *中的浮点模型(自那时以来可能已移至其他位置)。 - user743382DBL_MAX 精确地等于 (1 − b^−p)b^e_max,它是可以精确表示的,最小有限值精确地等于 -(1 − b^−p)b^e_max,并且由于这恰好是 -DBL_MAX,因此取反 DBL_MAX 也不会引入任何舍入误差。 - user743382浮点数(IEEE 754)是对称的,因此如果你可以表示最大值(DBL_MAX或numeric_limits<double>::max()),只需在其前面加上减号。
还有一种很酷的方式:
double f;
(*((uint64_t*)&f))= ~(1LL<<52);
在C语言中,使用
#include <float.h>
const double lowest_double = -DBL_MAX;
In C++pre-11, use
#include <limits>
const double lowest_double = -std::numeric_limits<double>::max();
#include <limits>
constexpr double lowest_double = std::numeric_limits<double>::lowest();
min()函数是不可用的吗?还是它与-max()表示的值不同?
http://en.cppreference.com/w/cpp/types/numeric_limits - Alexis Wilkemin可以得到绝对值最小的正数,而lowest可以得到绝对值最大的负数。是的,这很糟糕。欢迎来到 C++ 标准库的精彩世界 :-P。 - rubenvbfloat.h 中。而整数则需要使用 limits.h。 - Ciprian Tomoiagă试试这个:
-1 * numeric_limits<double>::max()
此类为每种基本类型进行了特化, 其成员返回或设置不同的值,这些值定义了该类型在特定平台上编译时具有的属性。
-numeric_limits<double>::max()? - k06a您是在寻找实际无限还是最小有限值?如果是前者,请使用
-numeric_limits<double>::infinity()
只有在某种情况下才有效
numeric_limits<double>::has_infinity
否则,您应该使用
numeric_limits<double>::lowest()
这是在C++11中引入的新特性。
如果lowest()不可用,您可以改为使用
-numeric_limits<double>::max()
在原则上,lowest() 可能与其不同,但通常实际上不会有区别。
-numeric_limits<double>::max() 并不完全可移植。 - Christophe从C++11开始,您可以使用numeric_limits<double>::lowest()。根据标准,它会返回您要查找的精确值:
一个有限的值x使得没有其他有限的值y满足
y < x。对于所有is_bounded != false的特化都是有意义的。
有很多答案都采用了-std::numeric_limits<double>::max()。
幸运的是,在大多数情况下,它们都能正常工作。浮点编码方案将数字分解为尾数和指数,并且大多数编码方案(例如流行的IEEE-754)使用不属于尾数的不同符号位。这使得通过翻转符号将最大的正数变成最小的负数。
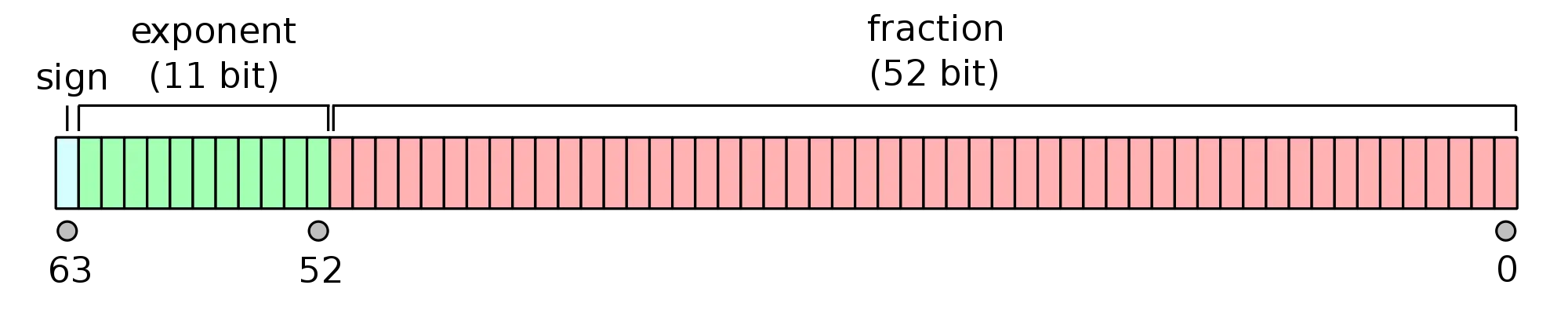
标准没有强制要求任何浮点标准。
我同意我的论点有些理论化,但假设某些古怪的编译器制造商使用一种革命性的编码方案,其中尾数使用某些变体的二进制补码进行编码。 二进制补码编码不是对称的。例如,对于带符号的8位char类型,最大正值为127,而最小负值为-128。因此,我们可以想象某些浮点编码显示类似的不对称行为。
我不知道是否存在这样的编码方案,但关键在于标准不能保证符号翻转产生所期望的结果。因此,这个流行的答案(对不起,伙计们!)不能被认为是完全可移植的标准解决方案! /* 至少在没有断言numeric_limits<double> ::is_iec559 为真的情况下 */
#include <math.h>
double most_negative = -INFINITY;
有没有一种标准和/或可移植的方法...?
现在我们还需要考虑其他情况:
只需使用-DBL_MAX。
在这种情况下,我认为OP会更喜欢-DBL_MAX。
DBL_MAX的大小还要大的非规范化值。这是一个不寻常的情况,可能超出了OP的关注范围。当double被编码为一对浮点数以实现所需的范围/精度时(参见double-double),存在一个最大的规范化double和一个更大的非规范化值。我已经看到有人争论DBL_MAX应该指的是最大的规范化,还是两者中最大的。
幸运的是,这种成对的方法通常包括一个负无穷大,因此最小值仍然是-INFINITY。
为了更好的可移植性,代码可以走这条路...
// HUGE_VAL is designed to be infinity or DBL_MAX (when infinites are not implemented)
// .. yet is problematic with unsigned infinity.
double most_negative1 = -HUGE_VAL;
// Fairly portable, unless system does not understand "INF"
double most_negative2 = strtod("-INF", (char **) NULL);
// Pragmatic
double most_negative3 = strtod("-1.0e999999999", (char **) NULL);
// Somewhat time-consuming
double most_negative4 = pow(-DBL_MAX, 0xFFFF /* odd value */);
// My suggestion
double most_negative5 = (-DBL_MAX)*DBL_MAX;
#define Infinity ((double)(42 / 0.0))
double neg_inf = -1/0.0;
这将产生负无穷大。如果您需要一个浮点数,您可以将结果转换为浮点数。
float neg_inf = (float)-1/0.0;
或使用单精度算术
float neg_inf = -1.0f/0.0f;
结果总是相同的,单精度和双精度都只有一种负无穷大的表示方式,并且它们之间的转换也如你所期望的那样。
-INFINITY,而要这样做呢? - M.Mneg_inf被初始化为常量值。编译器将负责计算inf值。当您将其用作计算最大值的空值时,第一次迭代通常会用更大的值覆盖它。也就是说,性能几乎不是问题。而且OP明确要求“例如使用负无穷大”,而-inf确实是唯一正确的答案。您已经对一个正确且有用的答案进行了负面评价。 - cmaster - reinstate monica