你可以使用简单的
map:
df.rdd.map(lambda row:
Row(row.__fields__ + ["day"])(row + (row.date_time.day, ))
)
另一种选择是注册一个函数并运行 SQL 查询:
sqlContext.registerFunction("day", lambda x: x.day)
sqlContext.registerDataFrameAsTable(df, "df")
sqlContext.sql("SELECT *, day(date_time) as day FROM df")
最后,您可以像这样定义自定义函数:
from pyspark.sql.functions import udf
from pyspark.sql.types import IntegerType
day = udf(lambda date_time: date_time.day, IntegerType())
df.withColumn("day", day(df.date_time))
编辑:
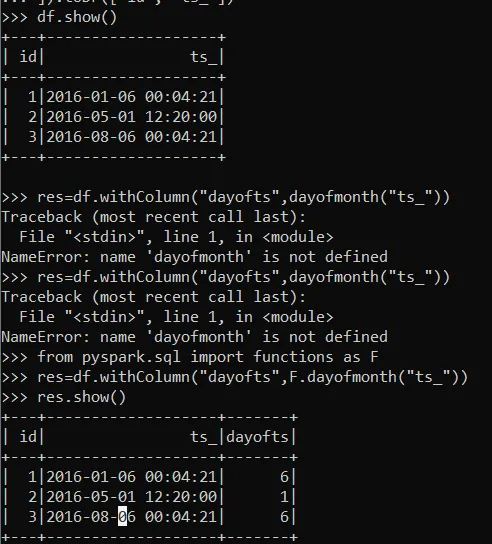
实际上,如果您使用原始的SQL语句,在Spark 1.4中day函数已经定义好了,因此您可以省略UDF注册。它还提供了许多不同的日期处理函数,包括:
还可以使用简单的日期表达式,例如:
current_timestamp() - expr("INTERVAL 1 HOUR")
这意味着您可以构建相对复杂的查询,而无需将数据传递给Python。例如:
df = sc.parallelize([
(1, "2016-01-06 00:04:21"),
(2, "2016-05-01 12:20:00"),
(3, "2016-08-06 00:04:21")
]).toDF(["id", "ts_"])
now = lit("2016-06-01 00:00:00").cast("timestamp")
five_months_ago = now - expr("INTERVAL 5 MONTHS")
(df
.withColumn("ts", unix_timestamp("ts_").cast("timestamp"))
.where(col("ts").between(five_months_ago, now))
.withColumn("next_sunday", next_day(col("ts"), "Sun"))
.withColumn("diff", datediff(col("ts"), col("next_sunday"))))