我想给以下的DataFrame添加一列(col5),其中col5中的值需要满足另一列在同一行中的特定条件,来自col4。例如,在col5的第1行,我希望从col4中选择一个值,使得col1和col2的值与第1行相同,但col3的值不等于第1行。在Excel中,可以使用sumifs函数来实现如下所示的操作。感谢任何帮助。
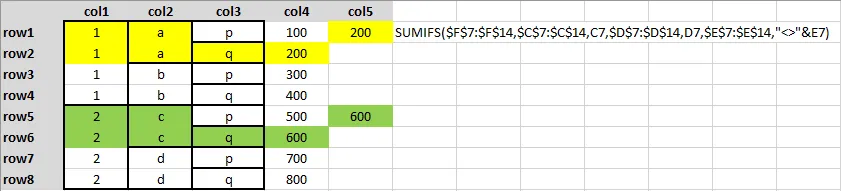 根据Paul的答案,我更新了我的问题。
根据Paul的答案,我更新了我的问题。
df=pd.DataFrame({"col1":[1,1,1,1,2,2,2,2], "col2":['a','a','b', 'b','c', 'c', 'd', 'd'], "col3":['p','q','p', 'q', 'p','q','p', 'q'], 'col4':[100,200,300,400,500,600,700,800]})
我想要实现的是像下面这样添加一个
col5,它会检查其他列中的条件,其中col1和col2应该相同,但col3不应匹配。假设col3只有两个不同的值,所以说col3不匹配意味着col3应该有另一个值。df2 = df
df['col5'] = df[(df.col1 == df2.col1) & (df.col2 == df2.col2) & (df.col3 != df2.col3)].col4
df
>>>
col1 col2 col3 col4 col5
0 1 a p 100 NaN
1 1 a q 200 NaN
2 1 b p 300 NaN
3 1 b q 400 NaN
4 2 c p 500 NaN
5 2 c q 600 NaN
6 2 d p 700 NaN
7 2 d q 800 NaN
运行此代码时,如上所示,我在
col5中得到所有的NaN。我想要得到的结果如下所示。这里的排列方式似乎很简单,就像从下一行或上一行获取一样,但在扩展数据中,它可能位于任何行。
>>>
col1 col2 col3 col4 col5
0 1 a p 100 200
1 1 a q 200 100
2 1 b p 300 400
3 1 b q 400 300
4 2 c p 500 600
5 2 c q 600 500
6 2 d p 700 800
7 2 d q 800 700