我研究了这个问题,人们一直建议使用
在组合中,元素不重复且无序。
以下不是组合:
np.meshgrid() 来找到一个数组的所有可能组合。但是问题在于,np.meshgrid() 产生的不是组合,而是乘积(类似于itertools.product())。在组合中,元素不重复且无序。
arr = np.arange(5)
r = 3
以下是组合的样子
np.array(
list(itertools.combinations(arr, r))
)
>>> [[0, 1, 2],
[0, 1, 3],
[0, 1, 4],
[0, 2, 3],
[0, 2, 4],
[0, 3, 4],
[1, 2, 3],
[1, 2, 4],
[1, 3, 4],
[2, 3, 4]]
以下不是组合:
np.array(
list(itertools.product(arr, arr, arr))
)
>>> [[0, 0, 0],
[0, 0, 1],
[0, 0, 2],
[0, 0, 3],
[0, 0, 4],
[0, 1, 0],
[0, 1, 1],
[0, 1, 2],
....,
[4, 3, 2],
[4, 3, 3],
[4, 3, 4],
[4, 4, 0],
[4, 4, 1],
[4, 4, 2],
[4, 4, 3],
[4, 4, 4]])
np.array(
np.meshgrid(arr, arr, arr)
).transpose([2, 1, 3, 0]).reshape(-1, r)
>>> [[0, 0, 0],
[0, 0, 1],
[0, 0, 2],
[0, 0, 3],
[0, 0, 4],
[0, 1, 0],
[0, 1, 1],
[0, 1, 2],
....,
[4, 3, 2],
[4, 3, 3],
[4, 3, 4],
[4, 4, 0],
[4, 4, 1],
[4, 4, 2],
[4, 4, 3],
[4, 4, 4]])
对于r = 2,我找到了一种简洁的组合方法。
np.array(
np.triu_indices(len(arr), 1)
).T
>>> [[0, 1],
[0, 2],
[0, 3],
[0, 4],
[1, 2],
[1, 3],
[1, 4],
[2, 3],
[2, 4],
[3, 4]]
但我很难找到任何适用于 r > 2 的向量化方法。
注意: 即使我的数组不是
[0, 1, 2, 3, 4],我也可以使用上面的答案作为索引。
如果有助于想象,
当 r = 2 时,所需答案是一个大小为 len(arr) 的正方形矩阵的右上角三角形的索引,忽略对角线。
当 r = 3 时,所需答案是一个大小为 len(arr) 的三维数组的顶部右上角上四面体(在图像中为中间位置),忽略三维等效的对角线。
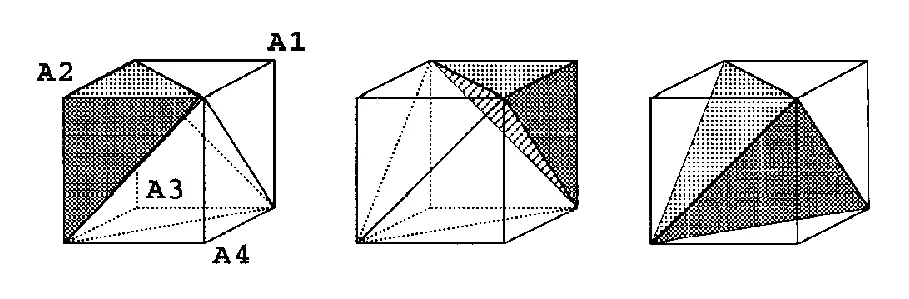
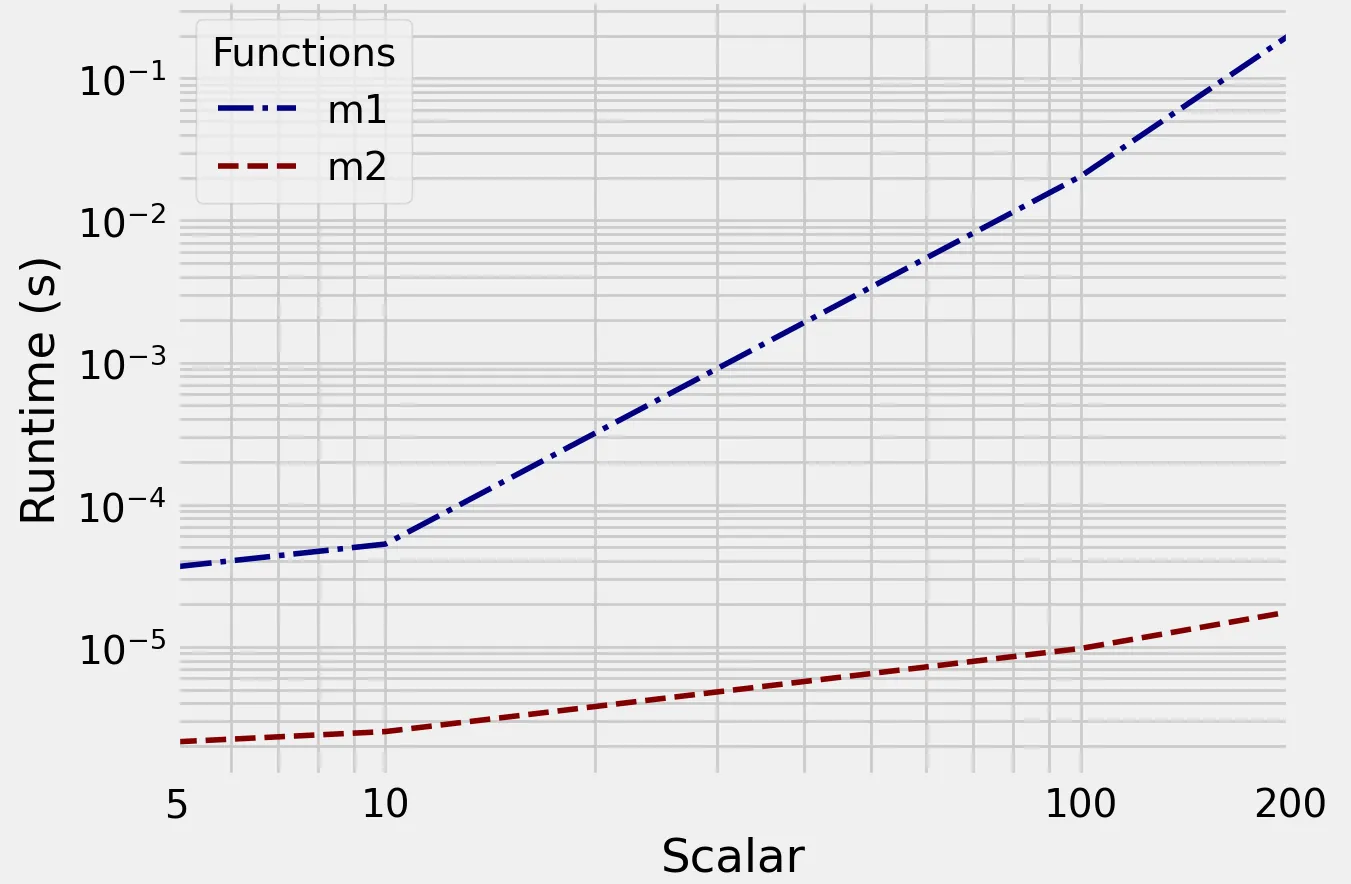
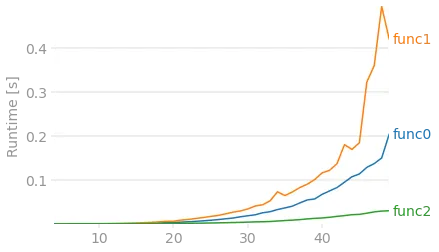
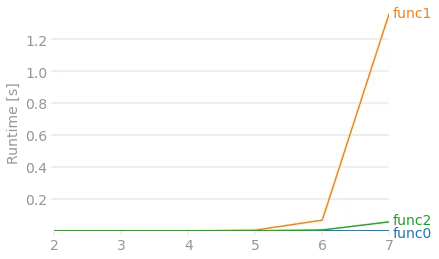
from itertools import permutationslist(permutations(arr, 3))可能。 - Scott Bostonitertools不可行。 - hammi