假设我有一个没有重复值的向量
c(1,2,3,4)。我需要一个向量c(1*2, 1*3, 1*4, 2*3, 2*4, 3*4),即对此向量的每个值进行所有可能的组合。是否有方法可以实现这一点?提前感谢!c(1,2,3,4)。我需要一个向量c(1*2, 1*3, 1*4, 2*3, 2*4, 3*4),即对此向量的每个值进行所有可能的组合。是否有方法可以实现这一点?提前感谢!combn(1:4, 2, "*")是最简单的解决方案,但实际上它不起作用。我们必须使用combn(1:4, 2, prod)如Onyambu所评论的。问题在于:在“N选K”设置中,FUN必须能够将长度为K的向量作为输入。 "*"不是正确的选项。## K = 2 case
"*"(c(1, 2)) ## this is different from: "*"(1, 2)
#Error in *c(1, 2) : invalid unary operator
prod(c(1, 2))
#[1] 2
感谢Maurits Evers对outer/lower.tri/upper.tri的解释。以下是一个改进的方法,可以避免从outer和*****.tri生成临时矩阵:
tri_ind <- function (n, lower= TRUE, diag = FALSE) {
if (diag) {
tmp <- n:1
j <- rep.int(1:n, tmp)
i <- sequence(tmp) - 1L + j
} else {
tmp <- (n-1):1
j <- rep.int(1:(n-1), tmp)
i <- sequence(tmp) + j
}
if (lower) list(i = i, j = j)
else list(i = j, j = i)
}
vec <- 1:4
ind <- tri_ind(length(vec), FALSE, FALSE)
#$i
#[1] 1 1 1 2 2 3
#
#$j
#[1] 2 3 4 3 4 4
vec[ind[[1]]] * vec[ind[[2]]]
#[1] 2 3 4 6 8 12
tri_ind函数是我在这个答案中的封装。它可以作为combn(length(vec), 2)或其outer等效的快速且节省内存的替代方案。
最初我链接了一个finv函数,但它不适合基准测试,因为它是设计用于从“dist”对象(已折叠的下三角矩阵)中提取少量元素。如果引用了三角矩阵的所有元素,则其索引计算实际上会带来不必要的开销。tri_ind是更好的选择。
library(bench)
bench1 <- function (n) {
bench::mark("combn" = combn(n, 2),
"tri_ind" = tri_ind(n, TRUE, FALSE),
"upper.tri" = which(upper.tri(matrix(0, n, n)), arr.ind = TRUE),
check = FALSE)
}
## for small problem, `tri_ind` is already the fastest
bench1(100)
# expression min mean median max `itr/sec` mem_alloc n_gc n_itr
# <chr> <bch:tm> <bch:tm> <bch:t> <bch:tm> <dbl> <bch:byt> <dbl> <int>
#1 combn 11.6ms 11.9ms 11.9ms 12.59ms 83.7 39.1KB 9 32
#2 tri_ind 189.3µs 205.9µs 194.6µs 4.82ms 4856. 60.4KB 21 1888
#3 upper.tri 618.4µs 635.8µs 624.1µs 968.36µs 1573. 411.7KB 57 584
## `tri_ind` is 10x faster than `upper.tri`, and 100x faster than `combn`
bench1(5000)
# expression min mean median max `itr/sec` mem_alloc n_gc
# <chr> <bch:tm> <bch:tm> <bch:tm> <bch:tm> <dbl> <bch:byt> <dbl>
#1 combn 30.6s 30.6s 30.6s 30.6s 0.0327 95.4MB 242
#2 tri_ind 231.98ms 259.31ms 259.31ms 286.63ms 3.86 143.3MB 0
#3 upper.tri 3.02s 3.02s 3.02s 3.02s 0.332 953.6MB 4
OP的问题的基准测试
bench2 <- function (n) {
vec <- numeric(n)
bench::mark("combn" = combn(vec, 2, prod),
"tri_ind" = {ind <- tri_ind(n, FALSE, FALSE);
vec[ind[[1]]] * vec[ind[[2]]]},
"upper.tri" = {m <- outer(vec, vec);
c(m[upper.tri(m)])},
check = FALSE)
}
bench2(100)
# expression min mean median max `itr/sec` mem_alloc n_gc n_itr
# <chr> <bch:tm> <bch:tm> <bch:t> <bch:tm> <dbl> <bch:byt> <dbl> <int>
#1 combn 18.6ms 19.2ms 19.1ms 20.55ms 52.2 38.7KB 4 22
#2 tri_ind 386.9µs 432.3µs 395.6µs 7.58ms 2313. 176.6KB 1 1135
#3 upper.tri 326.9µs 488.5µs 517.6µs 699.07µs 2047. 336KB 0 1024
bench2(5000)
# expression min mean median max `itr/sec` mem_alloc n_gc n_itr
# <chr> <bch:tm> <bch:tm> <bch:tm> <bch:t> <dbl> <bch:byt> <dbl> <int>
#1 combn 48.13s 48.13s 48.13s 48.13s 0.0208 95.3MB 204 1
#2 tri_ind 861.7ms 861.7ms 861.7ms 861.7ms 1.16 429.3MB 0 1
#3 upper.tri 1.95s 1.95s 1.95s 1.95s 0.514 810.6MB 3 1
combn并不是用编译代码编写的,它实际上在R级别内部使用了循环。各种替代方案只是试图在“N choose 2”情况下加速它,而不编写编译代码。gtools包中的函数combinations使用递归算法,对于大问题大小存在问题。来自combinat包的combn函数不使用编译代码,因此与R核心中的combn一样。Joseph Wood的RcppAlgos包具有最快的comboGenearl函数。library(RcppAlgos)
## index generation
bench3 <- function (n) {
bench::mark("tri_ind" = tri_ind(n, FALSE, FALSE),
"Joseph" = comboGeneral(n, 2), check = FALSE)
}
bench3(5000)
# expression min mean median max `itr/sec` mem_alloc n_gc n_itr
# <chr> <bch:tm> <bch:tm> <bch:tm> <bch:t> <dbl> <bch:byt> <dbl> <int>
#1 tri_ind 290ms 297ms 297ms 303ms 3.37 143.4MB 4 2
#2 Joseph 134ms 155ms 136ms 212ms 6.46 95.4MB 2 4
## on OP's problem
bench4 <- function (n) {
vec <- numeric(n)
bench::mark("tri_ind" = {ind <- tri_ind(n, FALSE, FALSE);
vec[ind[[1]]] * vec[ind[[2]]]},
"Joseph" = comboGeneral(vec, 2, constraintFun = "prod", keepResults = TRUE),
check = FALSE)
}
bench4(5000)
# expression min mean median max `itr/sec` mem_alloc n_gc n_itr
# <chr> <bch:tm> <bch:tm> <bch:tm> <bch:t> <dbl> <bch:byt> <dbl> <int>
#1 tri_ind 956ms 956ms 956ms 956ms 1.05 429MB 3 1
#2 Joseph 361ms 362ms 362ms 363ms 2.76 286MB 1 2
Joseph Wood在组合/排列问题上有多种答案。例如: combn的更快版本。
keepResults = TRUE 才能真正执行乘法。例如:comboGeneral(vec, 2, constraintFun = "prod", keepResults = TRUE)。好答案! - Joseph Woodcombn。combn(vec, 2, FUN = function(x) x[1] * x[2])
#[1] 2 3 4 6 8 12
vec <- 1:4
m <- outer(1:4, 1:4)
as.numeric(m[upper.tri(m)])
#[1] 2 3 6 4 8 12
upperouter <- function(x) {
N <- length(x)
i <- sequence(1:N)
j <- rep(1:N, 1:N)
(1:N)[i[i != j]] * (1:N)[j[j != i]]
}
upperouter(1:4)
#[1] 2 3 6 4 8 12
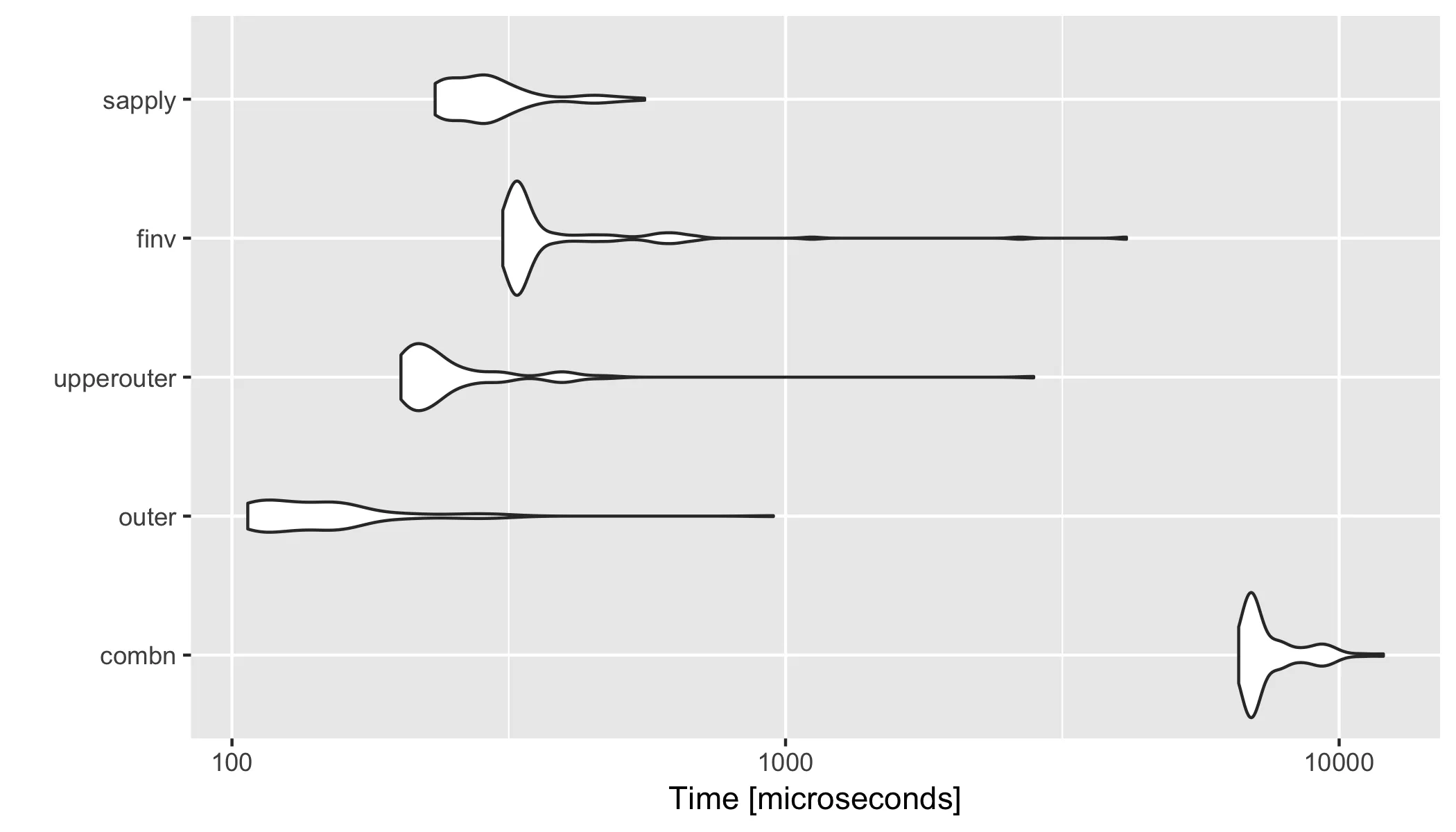
有趣的是,对于更大的vector(例如1:100),在microbenchmark分析中比较不同方法:
upperouter <- function(x) {
N <- length(x)
i <- sequence(1:N)
j <- rep(1:N, 1:N)
(1:N)[i[i != j]] * (1:N)[j[j != i]]
}
finv <- function (n) {
k <- 1:(n * (n - 1) / 2)
j <- floor(((2 * n + 1) - sqrt((2 * n - 1) ^ 2 - 8 * (k - 1))) / 2)
i <- j + k - (2 * n - j) * (j - 1) / 2
cbind(i, j)
}
N <- 100
library(microbenchmark)
res <- microbenchmark(
combn = combn(1:N, 2, prod),
outer = {
m <- outer(1:N, 1:N)
as.numeric(m[upper.tri(m)])
},
upperouter = {
upperouter(1:N)
},
finv = {
vec <- 1:N
ind <- finv(length(vec))
vec[ind[, 2]] * vec[ind[, 1]]
},
sapply = {
m <- sapply(1:N, "*", 1:N)
as.numeric(m[upper.tri(m)])
})
res
#Unit: microseconds
# expr min lq mean median uq max neval
# combn 6584.938 6896.0545 7584.8084 7035.9575 7886.5720 12020.626 100
# outer 106.791 113.6535 157.3774 138.9205 160.5985 950.706 100
# upperouter 201.943 210.1515 277.0989 227.6370 259.1975 2806.962 100
# finv 308.447 324.1960 442.3220 332.7250 375.3490 4128.325 100
# sapply 232.805 249.9080 298.3674 283.8580 315.9145 556.463 100
library(ggplot2)
autoplot(res)
(1:4%o%1:4)[lower.tri(diag(4))]。 - Onyambusapply而不是outer,那会怎样呢?基准测试结果是否仍然相同?例如:m=sapply(1:4,"*",1:4)? - Onyambuupperouter 直接索引上/下三角矩阵的元素。请看一下。 - Maurits Everssapply与outer/finv的表现相似,可以参考我的更新使用sapply。 - Maurits Evers
combn(1:4, 2, FUN = function(x) x[1] * x[2])- akruncombn(1:4, 2, prod)来实现。 - Onyambu"*"不起作用。 - Onyambuouter函数加上提取矩阵上/下三角部分的方法,即m <- outer(c(1, 2, 3, 4), c(1, 2, 3, 4)); as.numeric(m[upper.tri(m)])。 - Maurits Evers