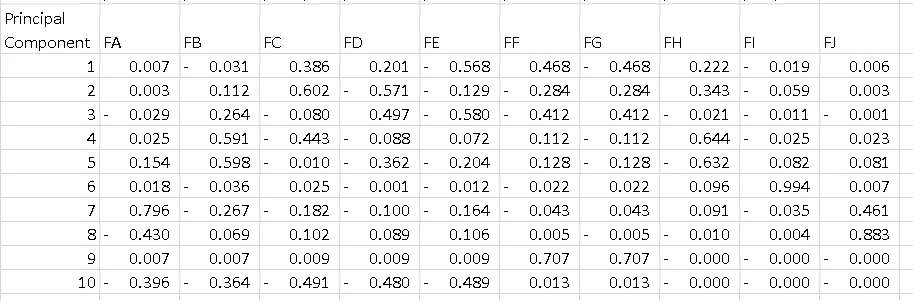
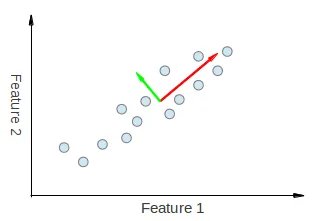
术语: 首先,PCA的结果通常以组件得分为讨论重点,有时称为因子得分(对应于特定数据点的变换后变量值),以及负载(用于将每个标准化原始变量乘以获取组件得分的权重)。
PART1: 我将解释如何检查特征的重要性并绘制双图。
PART2: 我将解释如何检查特征的重要性,并使用特征名称将它们保存到Pandas数据帧中。
Python紧凑指南总结: https://towardsdatascience.com/pca-clearly-explained-how-when-why-to-use-it-and-feature-importance-a-guide-in-python-7c274582c37e?source=friends_link&sk=65bf5440e444c24aff192fedf9f8b64f
PART1:
在您的情况下,Feature E 的值为-0.56是PC1上此特征的得分。 这个值告诉我们该特征对PC(在我们的情况下是PC1)的影响程度。
因此,绝对值越高,对主成分的影响就越大。
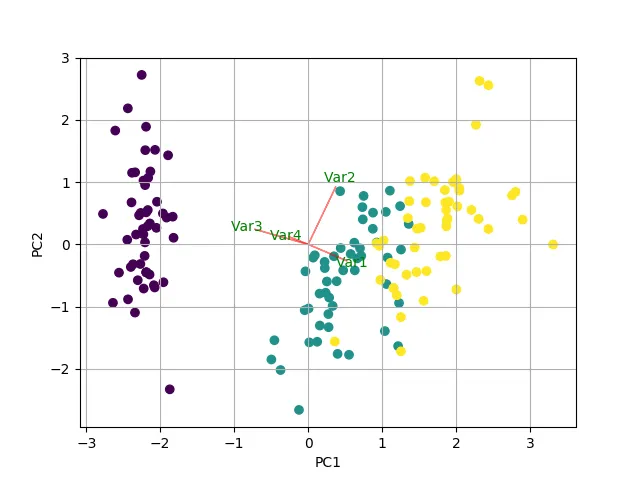
进行PCA分析后,人们通常绘制已知的“双图”,以查看N个维度中(在我们的情况下为2维),转换后的特征和原始变量(特征)。
我编写了一个函数来绘制此图。
示例使用鸢尾花数据:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
iris = datasets.load_iris()
X = iris.data
y = iris.target
scaler = StandardScaler()
scaler.fit(X)
X=scaler.transform(X)
pca = PCA()
pca.fit(X,y)
x_new = pca.transform(X)
def myplot(score,coeff,labels=None):
xs = score[:,0]
ys = score[:,1]
n = coeff.shape[0]
plt.scatter(xs ,ys, c = y)
for i in range(n):
plt.arrow(0, 0, coeff[i,0], coeff[i,1],color = 'r',alpha = 0.5)
if labels is None:
plt.text(coeff[i,0]* 1.15, coeff[i,1] * 1.15, "Var"+str(i+1), color = 'g', ha = 'center', va = 'center')
else:
plt.text(coeff[i,0]* 1.15, coeff[i,1] * 1.15, labels[i], color = 'g', ha = 'center', va = 'center')
plt.xlabel("PC{}".format(1))
plt.ylabel("PC{}".format(2))
plt.grid()
myplot(x_new[:,0:2], pca.components_)
plt.show()
结果
PART 2:
重要特征是那些对组件影响最大的,因此在组件上具有较大的绝对值。
要获取PC中最重要的特征,并将它们的名称保存到一个pandas数据框中,请使用以下代码:
from sklearn.decomposition import PCA
import pandas as pd
import numpy as np
np.random.seed(0)
train_features = np.random.rand(10,5)
model = PCA(n_components=2).fit(train_features)
X_pc = model.transform(train_features)
n_pcs= model.components_.shape[0]
most_important = [np.abs(model.components_[i]).argmax() for i in range(n_pcs)]
initial_feature_names = ['a','b','c','d','e']
most_important_names = [initial_feature_names[most_important[i]] for i in range(n_pcs)]
dic = {'PC{}'.format(i): most_important_names[i] for i in range(n_pcs)}
df = pd.DataFrame(dic.items())
这将打印:
0 1
0 PC0 e
1 PC1 d
在PC1上,特征e最重要,在PC2上是d。
文章摘要: Python紧凑指南:https://towardsdatascience.com/pca-clearly-explained-how-when-why-to-use-it-and-feature-importance-a-guide-in-python-7c274582c37e?source=friends_link&sk=65bf5440e444c24aff192fedf9f8b64f