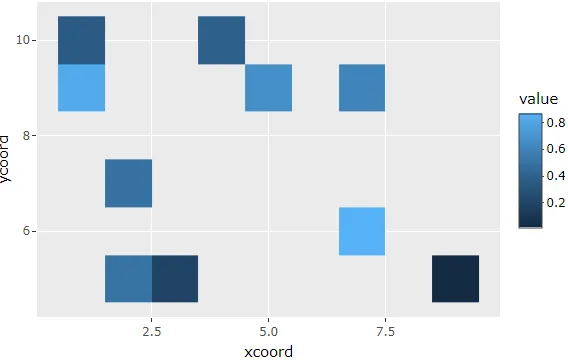
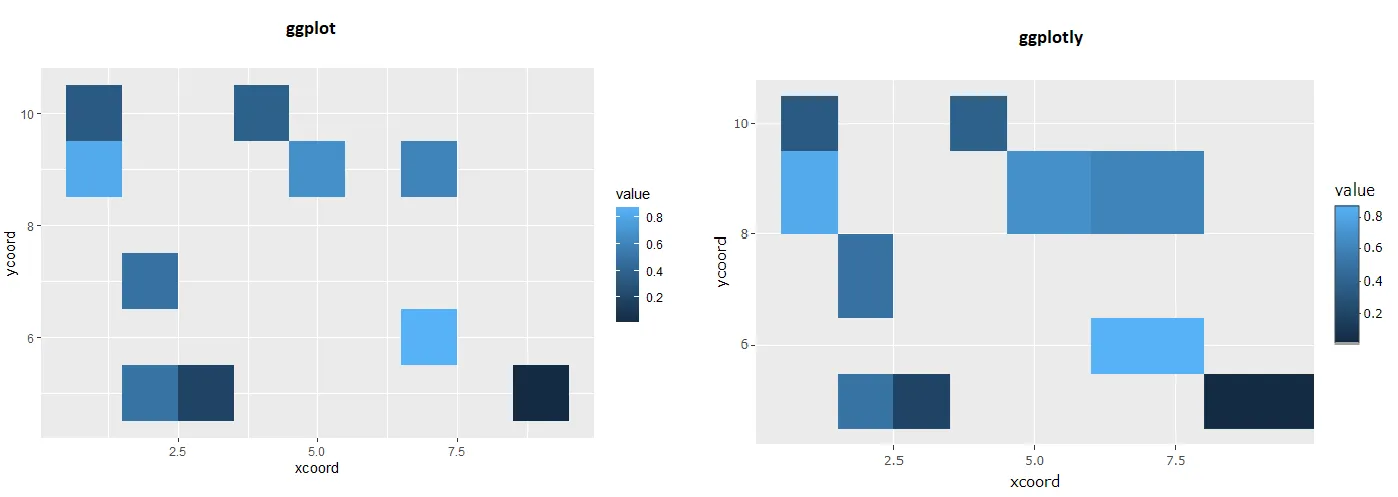
看一下plotly的代码
这里(以下是摘录),似乎栅格只对数据集中可用的任何x和y值进行定义,其余部分由plotly代码决定。
geom2trace.GeomTile <- function(data, params, p) {
x <- sort(unique(data[["x"]]))
y <- sort(unique(data[["y"]]))
g <- expand.grid(x = x, y = y)
g$order <- seq_len(nrow(g))
g <- merge(g, data, by = c("x", "y"), all.x = TRUE)
g <- g[order(g$order), ]
...
对于示例数据,此代码生成以下数据,其中灰色区域为NA,空白区域仅为未定义。所有扭曲/拉伸都发生在未定义的区域。
ggplot(g, aes(x = x, y = y, fill = value)) + geom_tile()
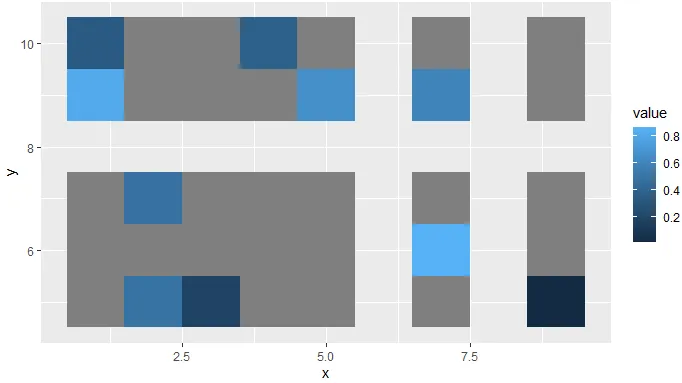
因此,解决方法之一(在 plotly 包之外)是手动确保整个 x/y 范围内都有(NA)数据可用,这样当图形转换为 plotly 时,expand.grid 会生成足够密集的网格。
set.seed(1)
X1 <- data.frame(xcoord = c(sample(1:10, n, replace = TRUE), 1:10),
ycoord = c(sample(1:10, n, replace = TRUE), 1:10),
value = c(runif(n), rep(NA, 10)))
gg1 <- ggplot(X1) + geom_tile(aes(x = xcoord, y = ycoord, fill = value))
ggplotly(gg1)
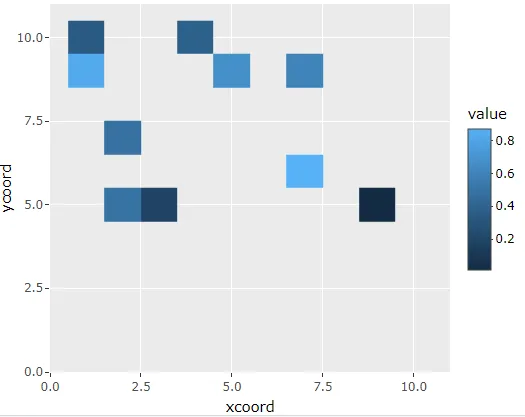
更新
虽然上面的例子演示了在数据集中对于任何x和y只需要一个值就足够,但是我还会添加一个更加简洁的解决方案,正如评论中Waldi所建议的那样。通过(自动)提前生成完整的网格,可以减少对plotly翻译的依赖。对于不同于1的网格间距,当然需要调整序列。
X2 <- tidyr::expand_grid(
xcoord = seq(min(X$xcoord), max(X$xcoord)),
ycoord = seq(min(X$ycoord),max(X$ycoord))
) %>%
dplyr::left_join(X, by=c('xcoord','ycoord'))
gg2 <- ggplot(X2) + geom_tile(aes(x = xcoord, y = ycoord, fill = value))
ggplotly(gg2)