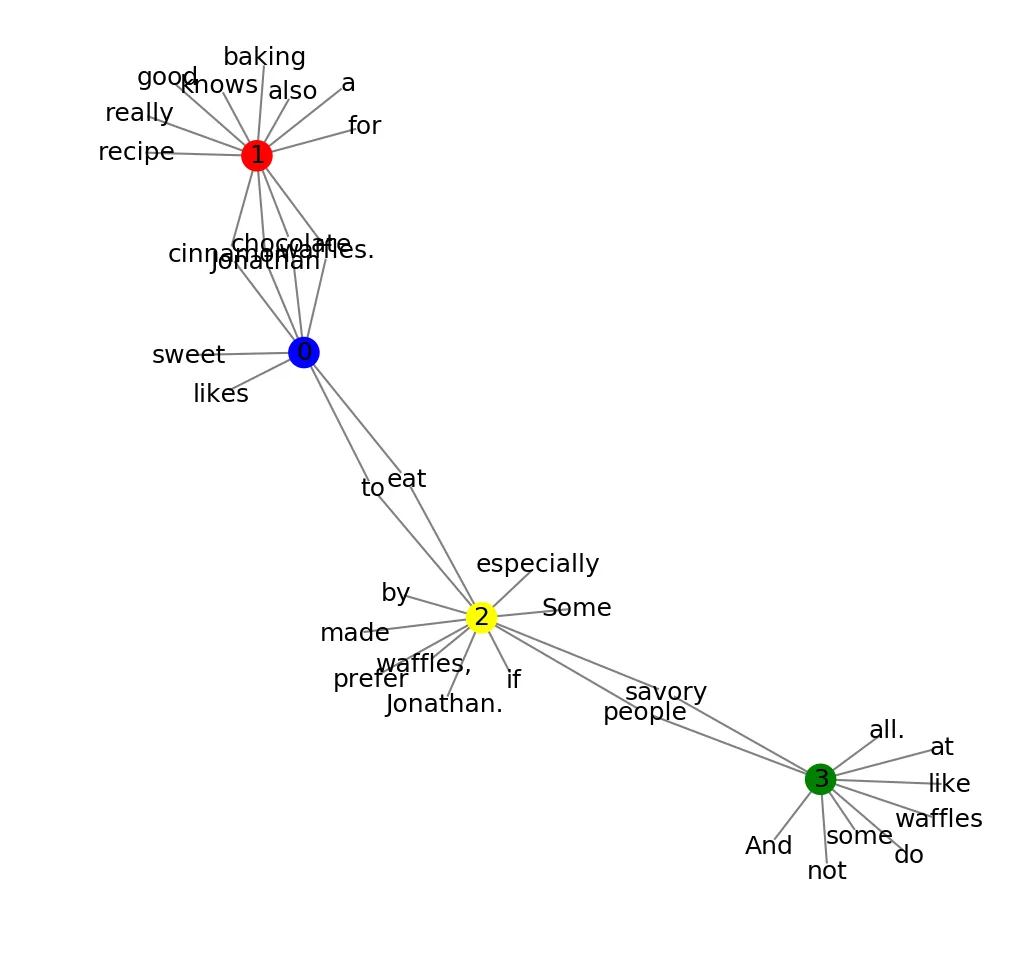
我想绘制一个图表,其中每个文档都有一个节点,然后每个单词都有另一个节点。这样,我想可视化在多个文档中出现的单词。
不幸的是,节点标签重叠在一起,因此有时它们并不容易阅读。
我已经尝试增加和减少变量k,但效果不太好。
我注意到如果重新绘制图形,图形会发生变化,并且有时标签更容易阅读,但这并不是很有帮助,因为我有几个更大的图形,需要确保它能正常工作,而不能依赖于重新绘制整个图形。
绘制的图表如下所示:
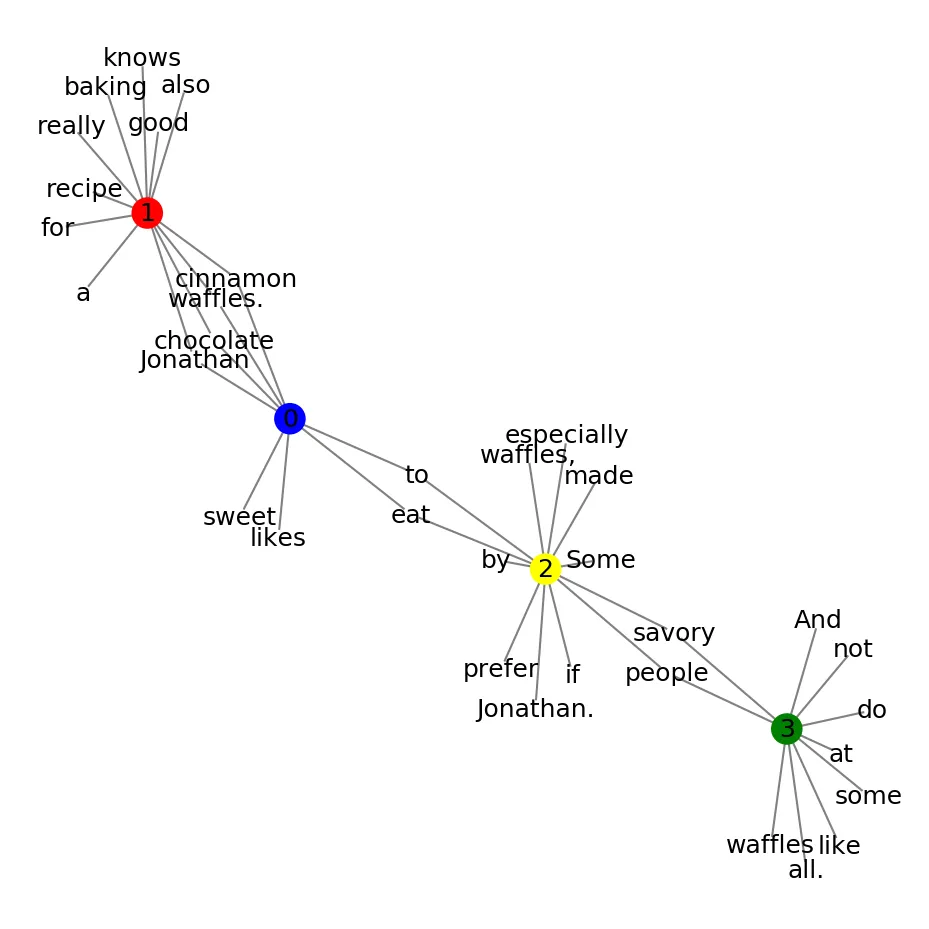
不幸的是,节点标签重叠在一起,因此有时它们并不容易阅读。
我已经尝试增加和减少变量k,但效果不太好。
我注意到如果重新绘制图形,图形会发生变化,并且有时标签更容易阅读,但这并不是很有帮助,因为我有几个更大的图形,需要确保它能正常工作,而不能依赖于重新绘制整个图形。
import networkx as nx
import matplotlib.pylab as plt
sentences = []
sentences.append("Jonathan likes to eat sweet cinnamon chocolate waffles.")
sentences.append("Jonathan also knows a really good recipe for baking cinnamon chocolate waffles.")
sentences.append("Some people prefer to eat savory waffles, especially if made by Jonathan.")
sentences.append("And some people do not like savory waffles at all.")
B=nx.from_dict_of_lists({0:[x for x in sentences[0].split()],1:[x for x in sentences[1].split()],2:[x for x in sentences[2].split()],
3:[x for x in sentences[3].split()]})
class_color=['blue','red','yellow','green']
node_color_array = []
nodesize = []
for node in B.nodes:
set_nodesize=50
color_to_add='white'
for x in range(4):
if(x==node):
set_nodesize=200
color_to_add =class_color[node]
node_color_array.append(color_to_add)
nodesize.append(set_nodesize)
plt.figure(5,figsize=(6,6), dpi=150, facecolor='w')
nx.draw(B,with_labels=True,node_color=node_color_array,node_size=nodesize,edge_color='grey')
plt.savefig('ExampleGraph.png')
绘制的图表如下所示: