我正在处理井孔的地下测量数据,每种测量类型覆盖不同深度范围。在这种情况下,深度被用作索引。
我需要找到每种测量类型第一个和/或最后一个数据(非NaN值)出现的深度(索引)。
获取数据框的第一行或最后一行的深度(索引)很容易:
我需要找到每种测量类型第一个和/或最后一个数据(非NaN值)出现的深度(索引)。
获取数据框的第一行或最后一行的深度(索引)很容易:
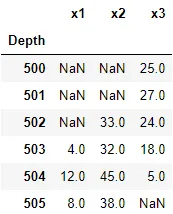
df.index[0] 或 df.index[-1]。关键是找到任何给定列的第一个或最后一个非NaN出现的索引。df = pd.DataFrame([[500, np.NaN, np.NaN, 25],
[501, np.NaN, np.NaN, 27],
[502, np.NaN, 33, 24],
[503, 4, 32, 18],
[504, 12, 45, 5],
[505, 8, 38, np.NaN]])
df.columns = ['Depth','x1','x2','x3']
df.set_index('Depth')
'x3',您如何决定它需要是最后一个有效索引,而不是第一个? - ALollzdf的第一行或最后一行索引不能用作解决方法。 - fact_finderdepth_df['x1']['min']或depth_df['x3']['max']来调用值。谢谢。 - fact_finder