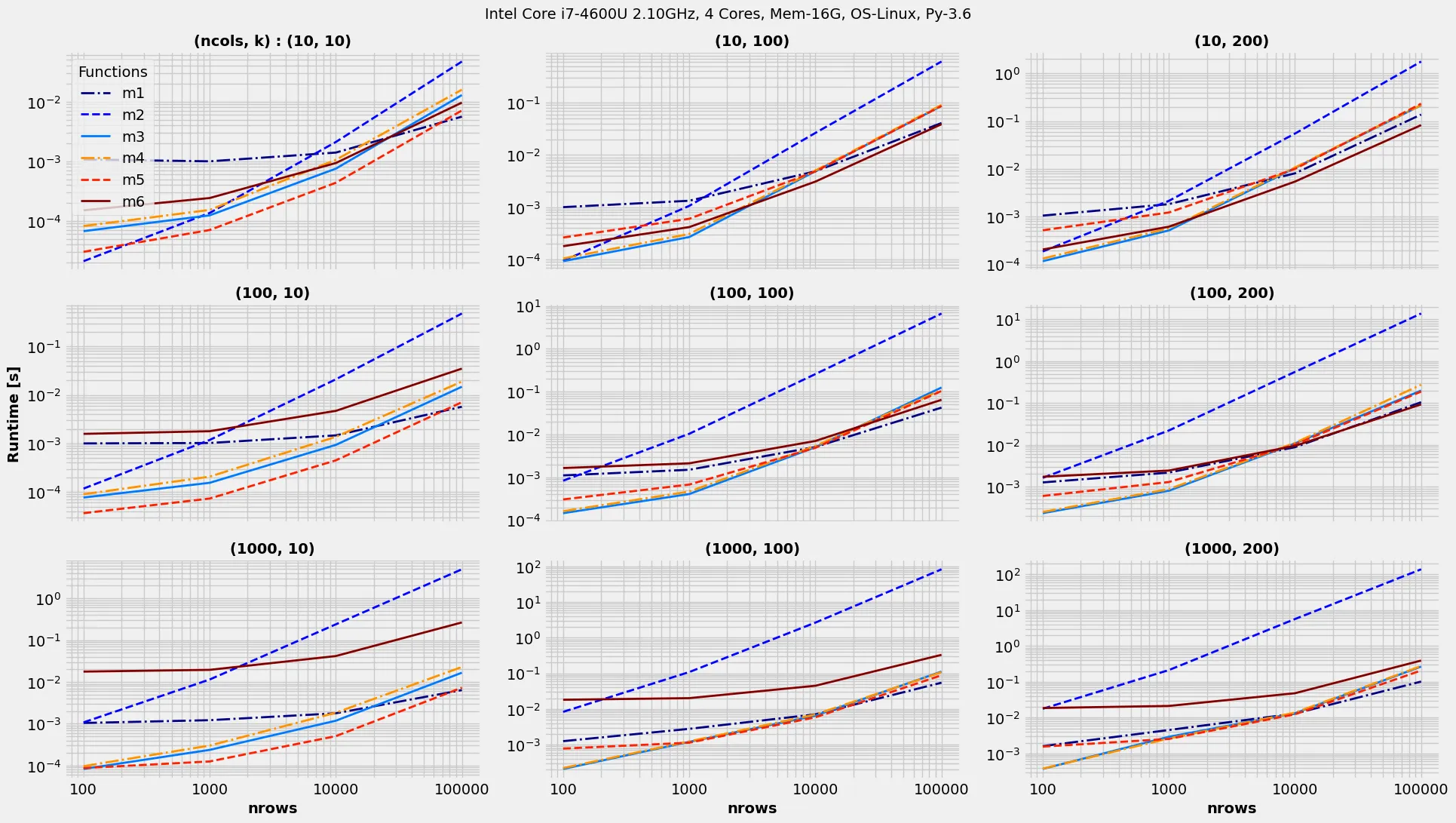
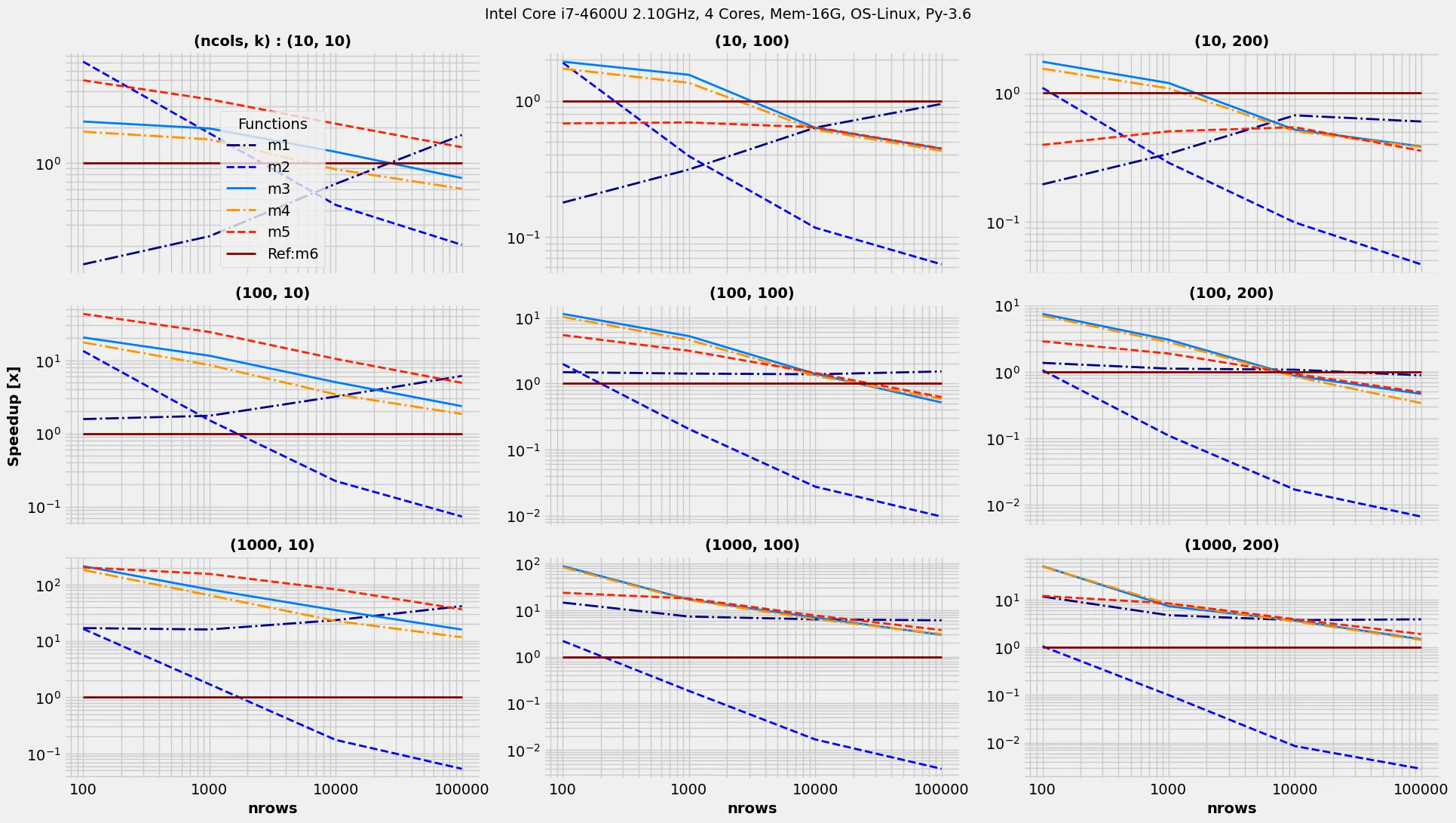
假设有一个形状为(r, c)的NumPy数组M,例如:
M = np.array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9],
[10, 11, 12],
[13, 14, 15]]) # r = 5; c = 3
有一个长度为r的一维数组a,其中包含0到k-1之间可变的整数,例如:
a = np.array([0, 0, 2, 1, 0]) # k = 4
我想使用
a中的值来选择M中的行,以获得如下中间结果:array([
[[1, 2, 3], [4, 5, 6], [13, 14, 15]] # rows of M where a == 0
[[10, 11, 12]], # rows of M where a == 1
[[7, 8, 9]] # rows of M where a == 2
[] # rows of M where a == 3 (there are none)
])
(我不需要这个中间数组,但只是为了说明而展示它。)返回的结果将是一个 (k, c) 数组,其中包含从此数组中按列计算的平均值:
array([[ 6., 7., 8.], # means where a == 0
[10., 11., 12.], # means where a == 1
[ 7., 8., 9.], # etc.
[nan, nan, nan]])
我可以使用以下方式完成此操作
np.array([M[a == i].mean(axis=0) for i in range(k)])
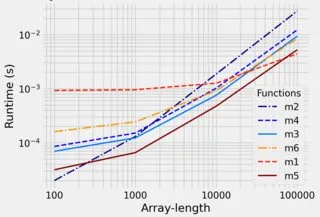
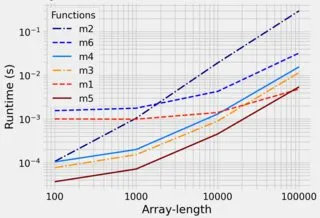
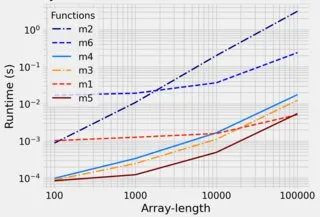
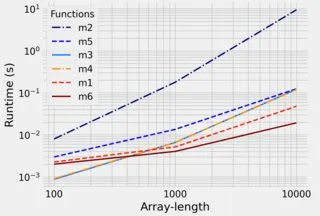
但是是否有一种方法(对于大的r和k来说更快),纯粹使用numpy方法而不是使用for循环来创建一个列表(然后必须将其转换回数组)?