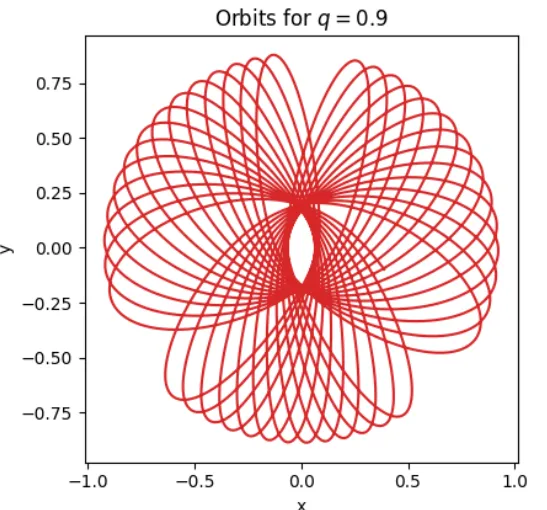
我有使用时间积分计算出的轨道,每个位置的坐标对应着 (x, y)。下图展示了这样一条轨道的示例:
 现在需要使用 x 和 y 的数组来构造以下序列:
现在需要使用 x 和 y 的数组来构造以下序列:
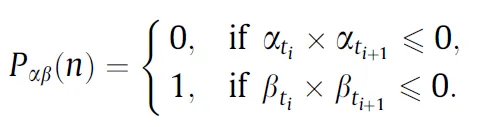 这实际上表示一个序列,其中 0 表示 x 在时间 t_n 和 t_n+1 之间改变了符号,而 1 则表示 y 在时间 t_n 和 t_n+1 之间改变了符号。
对于上述图片,该序列将如下所示:
这实际上表示一个序列,其中 0 表示 x 在时间 t_n 和 t_n+1 之间改变了符号,而 1 则表示 y 在时间 t_n 和 t_n+1 之间改变了符号。
对于上述图片,该序列将如下所示:
我实际上有两种计算方式: 第一种算法基于这个问题:“Efficiently detect sign-changes in python”,并使用了numpy:
第二个解决方案只是使用了一个简单的for循环:
现在需要使用 x 和 y 的数组来构造以下序列:
这实际上表示一个序列,其中 0 表示 x 在时间 t_n 和 t_n+1 之间改变了符号,而 1 则表示 y 在时间 t_n 和 t_n+1 之间改变了符号。
对于上述图片,该序列将如下所示:Pxy[n] = 1 0 1 0 1 0 ...
目前我已经找到多种解决方案,但它们在我使用的大型数据集上都非常慢。上述示例轨道的 x 和 y 坐标数组共有 10,000,000 个元素。由于为了足够精确,积分算法中的时间步长需要非常小,所以需要这么多的元素。我能想到的最快算法需要大约 5.3 秒才能运行。然而,这个相同的算法需要针对不同的轨道运行 100 多次。这意味着它将需要很长时间。我实际上有两种计算方式: 第一种算法基于这个问题:“Efficiently detect sign-changes in python”,并使用了numpy:
def calc_Pxy():
Pxy = np.full(x.shape, -1)
Pxy[np.where(np.diff(np.signbit(x)))] = 0
Pxy[np.where(np.diff(np.signbit(y)))] = 1
return Pxy[Pxy >= 0]
第二个解决方案只是使用了一个简单的for循环:
def calc_Pxy():
Pxy = []
for n, [xn, yn] in enumerate(zip(x[:-1], y[:-1])):
if xn * x[n + 1] < 0:
Pxy.append(0)
if yn * y[n + 1] < 0:
Pxy.append(1)
return np.array(Pxy)
!请看编辑! 经过对两种方法性能的测量,使用numpy的第一种方法似乎比普通的for循环慢2.5倍。
我的第一个问题是,为什么会这样?是因为需要重新调整数组大小,因此需要创建新的数组吗?
第二个问题是,我该如何才能比for循环更快呢?
最后,第一种numpy方法的另一个问题是,当x和y在同一时间步骤中都改变符号时,在第一个示例中只记录1次交叉,而在第二个示例中它将始终先记录x,然后是y的交叉。我更喜欢这样做,因为这样不会丢失任何数据。
如果您有任何改进性能的想法,将不胜感激。
编辑:在大型数据集上进行测试后,如果增加数据集的大小,numpy方法变得更快。我的初始测试基于20个值的小数据集,但对于100万个值,numpy方法更快。但是,我仍在寻找使该方法的行为与for循环相同的方法,并且任何进一步的速度提升也是受欢迎的。