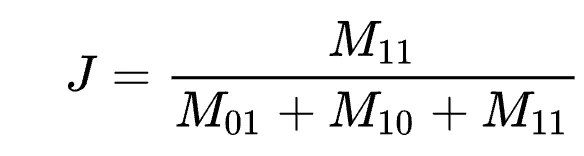可以使用scipy.spatial.distance.pdist计算Jaccard相似度分数。其中一个指标是'jaccard',它计算Jaccard不相似度(因此必须从1中减去得分以获得Jaccard相似度)。它返回一个1D数组,其中每个值对应于两列之间的Jaccard相似度。
可以通过构建MultiIndex来从分数构建Series。
from scipy.spatial.distance import pdist
jaccard_similarity = pd.Series(1 - pdist(df.values.T, metric='jaccard'), index=pd.MultiIndex.from_tuples([(c1, c2) for i, c1 in enumerate(df) for c2 in df.columns[i+1:]]))
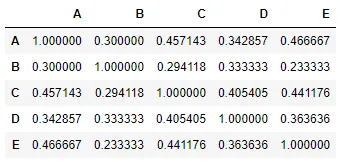
使用ayhan的设置,它会产生以下结果:
A B 0.300000
C 0.457143
D 0.342857
E 0.466667
B C 0.294118
D 0.333333
E 0.233333
C D 0.405405
E 0.441176
D E 0.363636
dtype: float64
如果需要一个矩阵,也可以从
pdist构建。只需构建一个空矩阵,并用这些值填充非对角线(对角线填1)。
from scipy.spatial.distance import pdist
def jaccard_similarity_matrix(df):
n = df.shape[1]
scores = 1 - pdist(np.array(df).T, metric='jaccard')
result = np.zeros((n,n))
result[np.triu_indices(n, k=1)] = scores
result += result.T
np.fill_diagonal(result, 1)
return pd.DataFrame(result, index=df.columns, columns=df.columns)
jaccard_similarity = jaccard_similarity_matrix(df)
事实上,通过使用
pdist的
源代码,也可以编写完全仅使用numpy和基本python的自定义函数。
def jaccard_matrix(df):
def jaccard(x, y):
nonzero = (x != 0) | (y != 0)
a = ((x != y) & nonzero).sum()
b = nonzero.sum()
return 1 - a / b if b != 0 else 1
arr = df.values
n = arr.shape[1]
scores = [jaccard(arr[:, i], arr[:, j]) for i in range(n-1) for j in range(i+1, n)]
result = np.zeros((n, n))
result[np.triu_indices(n, k=1)] = scores
result += result.T
np.fill_diagonal(result, 1)
return pd.DataFrame(result, index=df.columns, columns=df.columns)
所有这些函数返回相同的输出,可以通过以下方式进行验证:
df = pd.DataFrame(np.random.default_rng().binomial(1, 0.5, size=(100, 10))).add_prefix('col')
x = pd.DataFrame(1 - pairwise_distances(df.values.T.astype(bool), metric='jaccard'), index=df.columns, columns=df.columns)
y = jaccard_similarity_matrix(df)
z = jaccard_matrix(df)
np.allclose(x, y) and np.allclose(y, z)