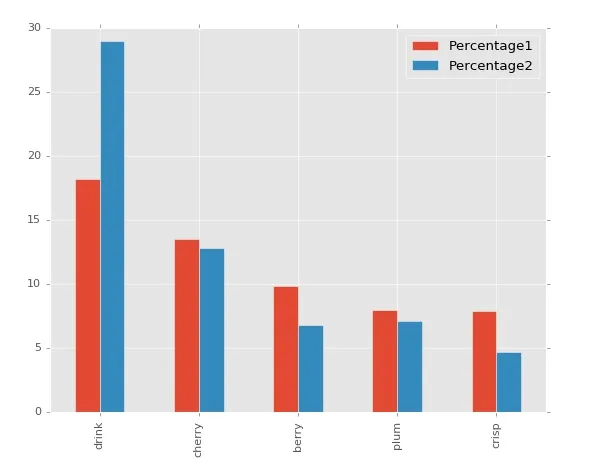
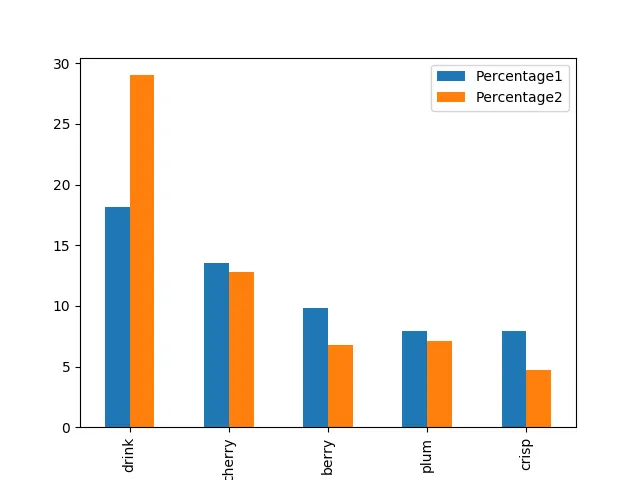
我有一个小的pandas数据帧,长这样:
import pandas as pd
data = {'Word': ['drink', 'cherry', 'berry', 'plum', 'crisp', 'spices'],
'Percentage1': [18.166654, 13.498262, 9.810123, 7.964429, 7.892941, 0.856775],
'Percentage2': [29.014272, 12.802642, 6.775552, 7.105845, 4.715009, 1.663586]}
df = pd.DataFrame(data)
Word Percentage1 Percentage2
0 drink 18.166654 29.014272
1 cherry 13.498262 12.802642
2 berry 9.810123 6.775552
3 plum 7.964429 7.105845
4 crisp 7.892941 4.715009
5 spices 0.856775 1.663586
这段文字涉及到IT技术,需要翻译的内容为:每个单词后面都有两列数字,分别表示该单词出现的次数。我该如何制作一个聚类图表,以展示每个单词的两个数字之间的比较?我已经尝试了其他网站上提供的所有代码,但我不知道如何将这两个“百分比”列分组。