这是一个迭代算法,关于矩阵更新,像素x聚类成员矩阵U(一行中的值之和必须为1.0),这是我想要优化的更新规则:
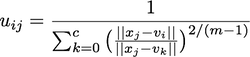
其中,x是矩阵X(像素x特征)的元素,v属于矩阵V(聚类x特征)。m是一个参数,范围从1.1到无穷大,c是聚类数。所使用的距离是欧几里得范数。
如果我要以平凡的方式实现这个公式,我会这样做:
for(int i = 0; i < X.length; i++)
{
int count = 0;
for(int j = 0; j < V.length; j++)
{
double num = D[i][j];
double sumTerms = 0;
for(int k = 0; k < V.length; k++)
{
double thisDistance = D[i][k];
sumTerms += Math.pow(num / thisDistance, (1.0 / (m - 1.0)));
}
U[i][j] = (float) (1f / sumTerms);
}
}
这样做已经进行了一些优化,我预先计算了X和V之间所有可能的平方距离,并将它们存储在矩阵D中,但这还不够,因为我正在循环遍历V的元素两次,导致有两个嵌套的循环。
观察公式,分数的分子与总和无关,因此我可以独立计算分子和分母,而分母可以针对每个像素只计算一次。
所以我想到了这样的解决方案:
int nClusters = V.length;
double exp = (1.0 / (m - 1.0));
for(int i = 0; i < X.length; i++)
{
int count = 0;
for(int j = 0; j < nClusters; j++)
{
double distance = D[i][j];
double denominator = D[i][nClusters];
double numerator = Math.pow(distance, exp);
U[i][j] = (float) (1f / (numerator * denominator));
}
}
在计算距离时,我将分母预先计算到矩阵D的附加列中:
for (int i = 0; i < X.length; i++)
{
for (int j = 0; j < V.length; j++)
{
double sum = 0;
for (int k = 0; k < nDims; k++)
{
final double d = X[i][k] - V[j][k];
sum += d * d;
}
D[i][j] = sum;
D[i][B.length] += Math.pow(1 / D[i][j], exp);
}
}
通过这样做,我在“平凡”的计算和第二个导致
U中不同数字值之间遇到了数值差异(不是在前几次迭代中,但很快就会出现)。我猜问题在于将非常小的数字乘以高值(U的元素范围从0.0到1.0,m = 1.1的exp为10),会导致非常小的值,而通过除分子和分母,然后再对结果进行指数运算,数值上似乎更好。问题是它涉及更多的操作。
更新
我在ITERATION 0处得到的一些值:
这是未经优化的矩阵D的第一行:
384.6632 44482.727 17379.088 1245.4205
这是经过优化的矩阵D的第一行(请注意,最后一个值是预先计算的分母):
384.6657 44482.7215 17379.0847 1245.4225 1.4098E-26
这是未优化的U的第一行:
0.99999213 2.3382613E-21 2.8218658E-17 7.900302E-6
这是优化后的U的第一行:
0.9999921 2.338395E-21 2.822035E-17 7.900674E-6
迭代 1:
这是未优化的矩阵D的第一行:
414.3861 44469.39 17300.092 1197.7633
这是优化后的矩阵D的第一行(请注意,最后一个值是预先计算的分母):
414.3880 44469.38 17300.090 1197.7657 2.0796E-26
这是未优化的U的第一行:
0.99997544 4.9366603E-21 6.216704E-17 2.4565863E-5
这是优化后的U的第一行:
0.3220644 1.5900239E-21 2.0023086E-17 7.912171E-6
最后一组值显示它们由于传播误差而非常不同(我仍然希望我犯了一些错误),即使这些值的总和必须为1.0的约束也被违反。
我做错了什么吗?有可能找到既可以优化代码又可以保持数值稳定的解决方案吗?任何建议或批评都将不胜感激。