我注意到在keras文档中有许多不同类型的Conv层,例如Conv1D、Conv2D、Conv3D。它们所有都有filters、kernel_size、strides和padding等参数,这些参数在其他keras层中不存在。
我看到过像这样的图像来“可视化”Conv层,
我看到过像这样的图像来“可视化”Conv层,
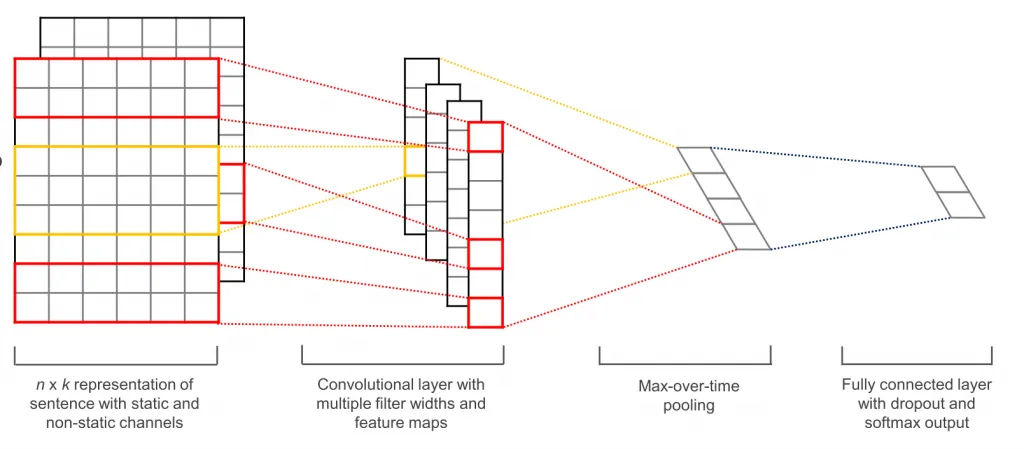
Conv层的尺寸将如何影响模型中发生的事情?
Conv层的尺寸将如何影响模型中发生的事情?卷积 - 通用基础知识
为了理解keras中的卷积是如何工作的,我们需要对在通用设置下卷积是如何工作有一个基本的了解。
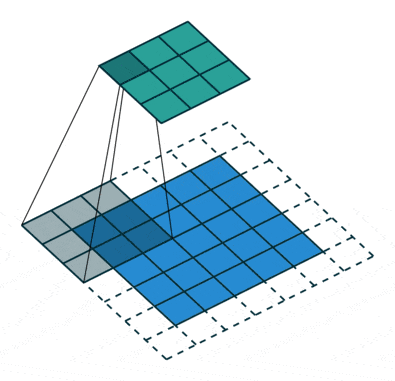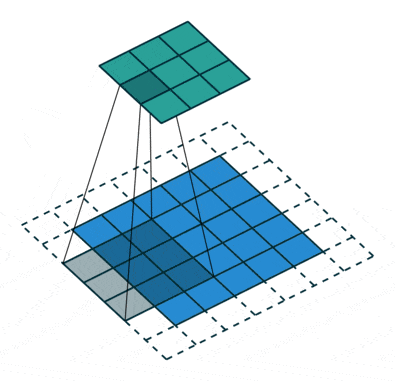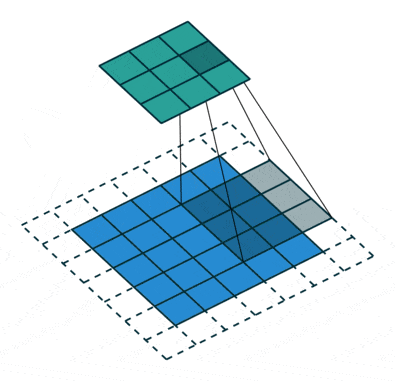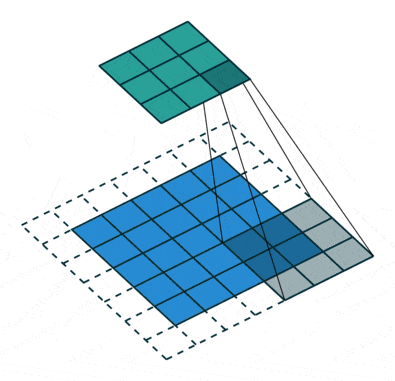
Keras提供了三种不同类型的填充方式。文档中的解释非常直观,因此在这里进行复制/改写。这些可以使用padding=...传递,例如padding="valid"。
valid:不填充
same:填充输入使得输出与原始输入具有相同的长度
causal:导致因果(扩张卷积)。通常,在上图中,内核的“中心”映射到输出激活图中的值。使用因果卷积时,使用右侧边缘。这对于时间数据非常有用,您不想使用未来数据来模拟现在的数据。
Conv1D、Conv2D和Conv3D
直观地说,这些层上发生的操作仍然相同。每个kernel仍然滑过您的输入,每个filter为其自身的特征输出一个激活图,并且仍然应用padding。
区别在于卷积的维数。例如,在Conv1D中,一维kernel沿一个轴滑动。在Conv2D中,二维kernel沿两个轴滑动。
非常重要的是,在X-D Conv层中,D并不表示输入的维数,而是内核滑过的轴数。

Conv2D层的示例。这是因为有两个空间维度-(行,列),而滤波器仅沿这两个维度滑动。您可以将其视为在空间维度上进行卷积,在通道维度上进行完全连接。Conv视为每个过滤器输出N-D向量。

Conv1D(如上图所示)中看到相同的情况。虽然输入是二维的,但滤波器只沿一个轴滑动,使其成为一维卷积。keras中,这意味着ConvND将要求每个样本具有N+1个维度-N个维度用于滤波器滑动,另外一个channels维度。
TLDR-Keras总结
filters:层中不同kernels的数量。每个kernel检测并输出特定功能的激活映射,从而成为输出形状中的最后一个值。即Conv1D输出(batch, steps, filters)。
kernel_size:确定每个kernel/filter/特征检测器的维度。还确定用于计算输出中每个值的输入量。较大的大小=检测更复杂的特征,约束较少;但容易过拟合。
strides:您移动多少个单位以进行下一次卷积。较大的步幅=更多信息丢失。
padding:可以是"valid","causal"或"same"。确定是否以及如何使用零填充输入。
1D vs 2D vs 3D: 表示卷积核滑动的轴数。一个N-D Conv层将为每个滤波器输出一个N-D输出,但对于每个样本,将需要一个N+1维度的输入。这由要横跨的N个维度加上一个额外的channels维度组成。
参考资料: