我开始使用Keras构建神经网络模型。
我有一个分类问题,其中特征是离散的。为了处理这种情况,标准程序是将离散特征转换为二进制数组,使用一位有效编码。
然而,在Keras中似乎不需要这一步,因为可以简单地使用嵌入层来创建这些离散特征的特征向量表示。
这些嵌入是如何进行的?
我的理解是,如果离散特征f可以取k个值,则嵌入层会创建一个具有k列的矩阵。每次在训练阶段收到该特征的一个值,例如i,则仅更新矩阵的i列。
我的理解正确吗?
我开始使用Keras构建神经网络模型。
我有一个分类问题,其中特征是离散的。为了处理这种情况,标准程序是将离散特征转换为二进制数组,使用一位有效编码。
然而,在Keras中似乎不需要这一步,因为可以简单地使用嵌入层来创建这些离散特征的特征向量表示。
这些嵌入是如何进行的?
我的理解是,如果离散特征f可以取k个值,则嵌入层会创建一个具有k列的矩阵。每次在训练阶段收到该特征的一个值,例如i,则仅更新矩阵的i列。
我的理解正确吗?
object_index_1: vector_1
object_index_1: vector_2
...
object_index_n: vector_n
选择特定对象的向量可以通过以下方式转换为矩阵乘积:
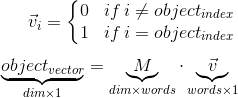
其中v是决定需要翻译哪个单词的one-hot向量。而M是嵌入矩阵。
如果我们提出通常的流程,它将如下所示:
objects = ['cat', 'dog', 'snake', 'dog', 'mouse', 'cat', 'dog', 'snake', 'dog']
unique = ['cat', 'dog', 'snake', 'mouse'] # list(set(objects))
objects_index = [0, 1, 2, 1, 3, 0, 1, 2, 1] #map(unique.index, objects)
objects_one_hot = [[1, 0, 0, 0], [0, 1, 0, 0], [0, 0, 1, 0], [0, 1, 0, 0],
[0, 0 , 0, 1], [1, 0, 0, 0], [0, 1, 0, 0], [0, 0, 1, 0], [0, 1, 0, 0]] # map(lambda x: [int(i==x) for i in range(len(unique))], objects_index)
#objects_one_hot is matrix is 4x9
#M = matrix of dim x 4 (where dim is the number of dimensions you want the vectors to have).
#In this case dim=2
M = np.array([[1, 1], [1, 2], [2, 2], [3,3]]).T # or... np.random.rand(2, 4)
#objects_vectors = M * objects_one_hot
objects_vectors = [[1, 1], [1, 2], [2, 2], [1, 2],
[3, 3], [1, 1], [1, 2], [2,2], [1, 2]] # M.dot(np.array(objects_one_hot).T)
通常,嵌入矩阵是在模型学习过程中学习的,以适应每个对象的最佳向量。我们已经有了对象的数学表示!
正如您所看到的,我们使用了一种独热编码和后续的矩阵乘积。您真正做的是取代表该单词的M列。
在学习过程中,M将被调整以改善对象的表示,并因此使损失下降。
很容易发现,在一个one-hot向量和一个Embedding矩阵相乘时,可以有效地在常数时间内执行,因为这可以理解为矩阵切片。这正是Embedding层在计算过程中所做的。它仅仅使用一个gather后端函数选择适当的索引。这意味着您对Embedding层的理解是正确的。
e = Embedding(1000, 64, input_length=50)
1000表示我们计划总共编码1000个单词。 64表示我们使用64维向量空间。 50表示输入文档每个有50个单词。
嵌入层将以非零值随机填充,并需要学习参数。
在这里创建嵌入层时还有其他参数。
嵌入层的输出是一个2D向量,其中包含输入序列(输入文档)中每个单词的一个嵌入。
注意:如果您想直接将一个Dense层连接到一个Embedding层,则必须先使用Flatten层将2D输出矩阵展平为1D向量。
当我们在处理任何领域(例如NLP)中的单词和句子时,我们喜欢以向量形式表示单词和句子,以便机器可以轻松识别单词并将其用于数学建模。例如,我们的词汇表中有10个单词,我们希望每个单词都能独特地表示。最简单的方法是为每个单词分配一个数字,并创建一个具有10个元素的向量,仅激活具有该数字的元素并停用所有其他元素。例如,在我们的词汇表中,dog是一个单词,我们将数字3分配给它,因此向量将类似于
{0,0,1,0,0,0,0,0,0,0}
对于其他单词,它们将激活其他元素。上述示例非常简单但效率极低。假设我们的词汇表中有100000个单词,为了表示这100000个单词,我们将拥有100000 [1*100000]向量。因此,要高效地完成此任务,我们可以使用嵌入技术。它们以密集形式表示单词(例如仅具有32个元素的向量)。Dog可以表示为:
{0.24,0.97}
从数学建模的角度来看,这种方法更加高效和优越。