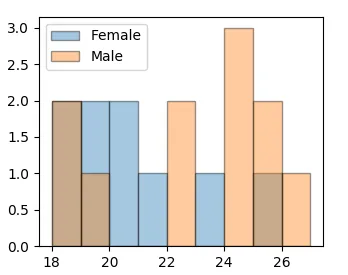
我相信这个问题有一个简单的答案,只是我看事情的角度不对。关于我的pyplot直方图出现了什么问题?下面是输出结果;数据包含年龄在18至24岁之间的参与者,没有小数年龄(没有人是18.5岁):
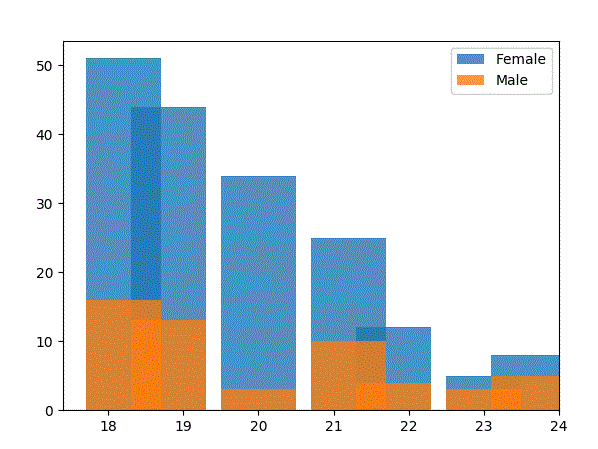
为什么垃圾桶会这样错落有致?当前宽度设置为1,所以每个条形图应该是一个垃圾桶的宽度,对吧?当宽度小于0.5时,问题变得更加严重,此时条形图看起来就像在完全不同的垃圾桶中。
以下是代码:
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
csv = pd.read_csv('F:\Python\Delete\Delete.csv')
age = csv.age
gender = csv.gender
new_age = age[~np.isnan(age)]
new_age_f = new_age[gender==2]
new_age_m = new_age[gender==1]
plt.hist(new_age_f, alpha=.80, label='Female', width=1, align='left')
plt.hist(new_age_m, alpha=.80, label='Male', width=1, align='left')
plt.legend()
plt.show()
谢谢!