我调用了一个webservice,返回一个采用UTF-8编码的响应xml,我在Java中使用getAllHeaders() 方法来检查。
现在,在我的Java代码中,我对该响应进行一些处理。之后,将其传递给另一个服务。
我通过谷歌搜索发现,Java字符串默认的编码方式是UTF-16。
在我的响应xml中,有一个元素具有字符É。但是,在我向不同服务发出后处理请求时,该字符被破坏了。
它发送了一些乱码。我想知道这两种编码之间是否会有很大的区别?如果我想知道É将从UTF-8转换为UTF-16,我应该如何做?
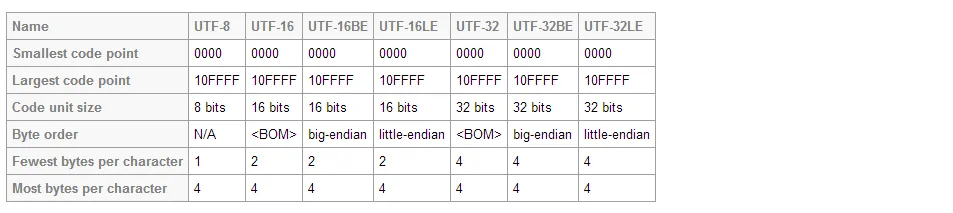 UTF-8 和 UTF-16 都是可变长度编码。但是,在 UTF-8 中,一个字符至少占用 8 个比特,而在 UTF-16 中,字符长度从 16 比特开始。
UTF-8 和 UTF-16 都是可变长度编码。但是,在 UTF-8 中,一个字符至少占用 8 个比特,而在 UTF-16 中,字符长度从 16 比特开始。