UTF-8、UTF-16和UTF-32有什么区别?
我理解它们都可以存储Unicode,并且每种编码使用不同数量的字节来表示字符。是否有选择一种编码比另一种更具优势的情况呢?
UTF-8、UTF-16和UTF-32有什么区别?
我理解它们都可以存储Unicode,并且每种编码使用不同数量的字节来表示字符。是否有选择一种编码比另一种更具优势的情况呢?
UTF-8在大部分字符为ASCII字符的文本块中具有优势,因为UTF-8将这些字符编码为8位(与ASCII相同)。同时,仅包含ASCII字符的UTF-8文件与ASCII文件具有相同的编码。
当ASCII字符不占主导地位时,UTF-16更好,因为它主要使用每个字符2个字节。当UTF-8开始使用3个或更多字节表示高阶字符时,UTF-16仍然保持大部分字符只需2个字节。
UTF-32在4个字节中涵盖所有可能的字符,这使其变得臃肿。我无法想到任何使用它的优点。
简而言之:
wchar_t 默认为 4 个字节。gcc有一个选项 -fshort-wchar 可以将其减小到2个字节,但会破坏与标准库的二进制兼容性。 - vine'thUTF-8 可变长,使用 1 到 4 个字节。
UTF-16 可变长,使用2 或 4个字节。
UTF-32 固定长度,使用 4 个字节。
UTF-16是一种妥协。它允许大多数字符适合固定宽度的16位值中。因此,只要不涉及汉字、乐符或其他某些字符,可以假设每个字符宽度为16位。它比UTF-32使用更少的内存。但在某些方面它是“两难之最”。它几乎总是比UTF-8使用更多的内存,而且它仍然无法避免困扰UTF-8的问题(可变长度字符)。
最后,通常最好按照平台所支持的方式进行操作。Windows在内部使用UTF-16,因此在Windows上,UTF-16显然是明智的选择。
Linux有点不同,但他们通常会对符合Unicode标准的所有内容使用UTF-8。
简而言之:所有三种编码都可以编码相同的字符集,但它们将每个字符表示为不同的字节序列。
Unicode是一种标准,而UTF-x则可以看作是针对某些实际目的的技术实现:
我在我的博客文章中尝试给出一个简单的解释。
需要32位(4个字节)来编码任何字符。例如,为了用这种方案表示“A”字符的代码点,你需要用32位二进制数写出65:
00000000 00000000 00000000 01000001 (Big Endian)
仔细观察会发现,最右边的七位实际上是使用ASCII方案时相同的位。但由于UTF-32是一种固定宽度格式,因此我们必须附加三个额外的字节。这意味着,如果我们有两个仅包含字符"A"的文件,一个是ASCII编码,另一个是UTF-32编码,它们的大小分别为1字节和4字节。
许多人认为,由于UTF-32使用固定宽度的32位来表示代码点,所以UTF-16使用了固定宽度的16位。这是错误的!
在UTF-16中,代码点可以用16位或32位表示。因此,这个方案是一种可变长度编码系统。与UTF-32相比,优势在哪里?至少对于ASCII,文件大小不会增加到原来的四倍(但仍然是两倍),因此我们仍然不兼容ASCII。
由于7位足以表示字符"A",因此我们现在可以使用2个字节代替UTF-32的4个字节。它看起来像:
00000000 01000001
在UTF-8编码中,字符的编码长度可能为32、16、24或8位。和UTF-16一样,这也是一种可变长度编码系统。
最终,我们可以用与ASCII编码系统相同的方式来表示“A”:
01001101
考虑中文字符“語” - 它的UTF-8编码为:
11101000 10101010 10011110
虽然它的UTF-16编码更短:
10001010 10011110
为了理解这个表述及其解释,请访问原始文章。
除非大部分字符来自 CJK(中文,日语和韩语)字符空间,否则 UTF-8 将是最节省空间的。
对于通过字符偏移量随机访问字节数组,UTF-32 是最佳选择。
0xxxxxxx 的形式。所有双字节字符以 110xxxxx 开头,第二个字节为 10xxxxxx。所以假设一个双字节字符的第一个字符丢失了。一旦你看到 10xxxxxx 而没有前导的 110xxxxxx,你就可以确定一个字节已经丢失或损坏,并且丢弃该字符(或从服务器重新请求它),然后继续直到再次看到有效的第一个字节。 - Chris - Regenerate Response在UTF-32中,每个字符都是用32位进行编码。优点是可以轻松计算字符串的长度。缺点是,对于每个ASCII字符,您浪费了额外的三个字节。
在UTF-8中,字符具有可变长度,ASCII字符编码为一个字节(八位),大多数西方特殊字符编码为两个或三个字节(例如€为三个字节),更奇异的字符可以占用最多四个字节。明显的缺点是,您无法先验地计算字符串的长度。但与UTF-32相比,使用拉丁(英语)字母文本需要的字节数要少得多。
UTF-16也具有可变长度。 字符编码为两个或四个字节。我真的看不出有什么意义。它具有可变长度的缺点,但没有像UTF-8那样节省空间的优势。
在这三个中,显然UTF-8是最广泛使用的。
我进行了一些测试,比较了MySQL中UTF-8和UTF-16之间的数据库性能。


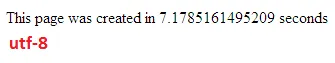
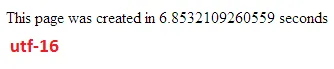
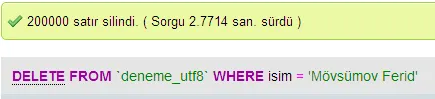
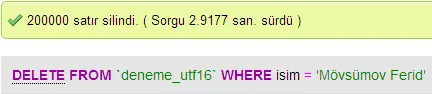
我很惊讶这个问题已经有11年历史了,但没有一个答案提到utf-8的#1优点。
utf-8通常即使在不支持utf-8的程序中也能正常工作。这部分是它被设计出来的原因之一。其他答案提到前128个代码点与ASCII相同。所有其他代码点都是由高位设置为1的8位值生成的(值从128到255),因此从非Unicode知道的程序的角度来看,它只是看到字符串是带有一些额外字符的ASCII。
举个例子,假设你写了一个程序添加行号,实际上就像这样(为了保持简单,我们假设行尾只是ASCII 13):
// pseudo code
function readLine
if end of file
return null
read bytes (8bit values) into string until you hit 13 or end or file
return string
function main
lineNo = 1
do {
s = readLine
if (s == null) break;
print lineNo++, s
}
将utf-8文件传递给此程序仍然可以正常工作。类似地,以制表符、逗号分隔、解析ASCII引号或其他仅与ASCII值相关的解析都可以使用utf-8正常运行,因为在utf-8中除非它们实际上是那些ASCII值,否则不会出现ASCII值
其他一些答案或评论提到utf-32的优点是您可以单独处理每个码点。例如,这将建议您可以获取像“ABCDEFGHI”这样的字符串,并在每第3个码点处拆分它以进行操作。
ABC
DEF
GHI
因此,UTF-32 不会让您毫无顾虑地随意操作 Unicode 字符串,它只允许您使用最基本的代码点而无需额外的代码。
- 这行文字并没有反向输入,只是显示出来反向罢了。
| 字节数 | 第一个代码点 | 最后一个代码点 | 字节 1 | 字节 2 | 字节 3 | 字节 4 |
|---|---|---|---|---|---|---|
| 1 | U+0000 |
U+007F |
0xxxxxxx |
|||
| 2 | U+0080 |
U+07FF |
110xxxxx |
10xxxxxx |
||
| 3 | U+0800 |
U+FFFF |
1110xxxx |
10xxxxxx |
10xxxxxx |
|
| 4 | U+10000 |
U+10FFFF |
11110xxx |
10xxxxxx |
10xxxxxx |
10xxxxxx |
xxxxxx 是代码点的位,将每个字节的 xxxx 位连接起来即可得到代码点。