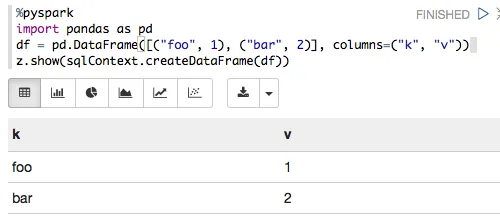
我是zeppelin的新手。我有一个使用案例,其中我有一个pandas数据帧。我需要使用zeppelin的内置图表来可视化集合,但我在这里没有清晰的方法。我的理解是,如果数据以RDD格式存在,则可以使用zeppelin可视化数据。因此,我想将pandas数据帧转换为spark数据帧,然后进行一些查询(使用sql),我将进行可视化。 首先,我尝试将pandas数据帧转换为spark数据帧,但失败了。
%pyspark
import pandas as pd
from pyspark.sql import SQLContext
print sc
df = pd.DataFrame([("foo", 1), ("bar", 2)], columns=("k", "v"))
print type(df)
print df
sqlCtx = SQLContext(sc)
sqlCtx.createDataFrame(df).show()
我收到了以下错误
Traceback (most recent call last): File "/tmp/zeppelin_pyspark.py",
line 162, in <module> eval(compiledCode) File "<string>",
line 8, in <module> File "/home/bala/Software/spark-1.5.0-bin-hadoop2.6/python/pyspark/sql/context.py",
line 406, in createDataFrame rdd, schema = self._createFromLocal(data, schema) File "/home/bala/Software/spark-1.5.0-bin-hadoop2.6/python/pyspark/sql/context.py",
line 322, in _createFromLocal struct = self._inferSchemaFromList(data) File "/home/bala/Software/spark-1.5.0-bin-hadoop2.6/python/pyspark/sql/context.py",
line 211, in _inferSchemaFromList schema = _infer_schema(first) File "/home/bala/Software/spark-1.5.0-bin-hadoop2.6/python/pyspark/sql/types.py",
line 829, in _infer_schema raise TypeError("Can not infer schema for type: %s" % type(row))
TypeError: Can not infer schema for type: <type 'str'>
有人能帮我一下吗?如果我哪里说错了,请纠正我。