我正在运行一个带有两个工作节点的Spark流式应用程序。该应用包含联接和合并操作。
所有批次都成功完成,但是注意到Shuffle溢出指标与输入数据大小或输出数据大小不一致(溢出内存超过20倍)。
请在下面的图片中查找Spark阶段详细信息:
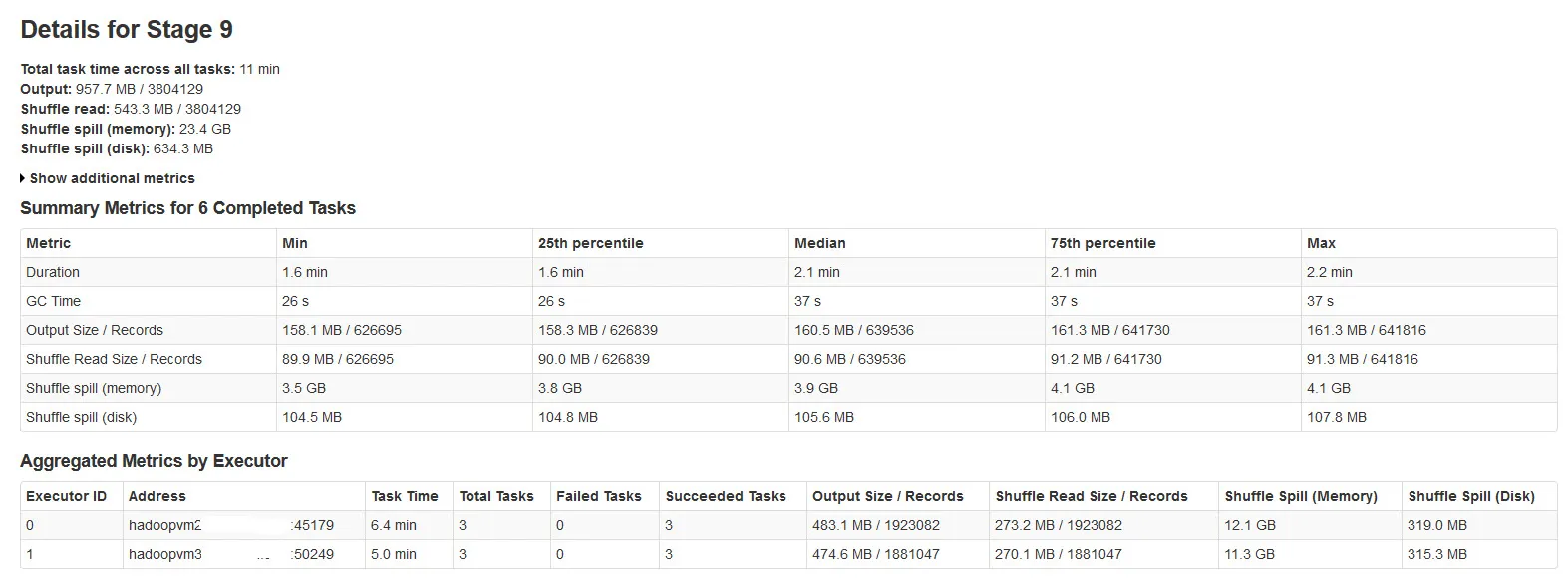
经过调查,发现:
当Shuffle数据没有足够的内存时,就会发生Shuffle溢出。
Shuffle spill (memory) - 溢出时在内存中反序列化数据的大小
shuffle spill (disk) - 溢出后磁盘上数据的序列化形式的大小
由于反序列化数据占用的空间比序列化数据更大。所以,Shuffle溢出(内存)更多。
注意到这个溢出内存大小在有大量输入数据时非常大。
我的问题是:
这种溢出会显著影响性能吗?
如何优化此溢出内存和磁盘溢出?
是否有任何Spark属性可以减少/控制这个巨大的溢出?