阅读了一些在线论坛和stackoverflow的问题后,我理解的是:
当执行程序用尽其内存时,数据溢出会发生。而洗牌溢出(内存)是在我们将其溢出时内存中数据的反序列化形式的大小。
我正在本地运行spark,并将spark driver memory设置为10g。
如果我的理解是正确的,那么如果groupBy操作需要超过10GB的执行内存,则必须将数据溢出到磁盘上。
假设一个groupBy操作需要12GB内存,由于驱动器内存设置为10GB,它必须将近2GB的数据溢出到磁盘上,因此Shuffle Spill(Disk)应该是2GB,Shuffle spill(memory)应该是剩余的10GB,因为Shuffle spill(memory)是溢出时内存中数据的大小。
如果我的理解是正确的,那么Shuffle spill(memory)<= Executor memory。在我的情况下,它是驱动器内存,因为我正在本地运行spark。
但似乎我漏掉了什么,下面是来自spark ui的值。
即使我将Spark驱动程序内存设置为
我观察到Windows任务管理器中的内存消耗在作业运行时从未超过
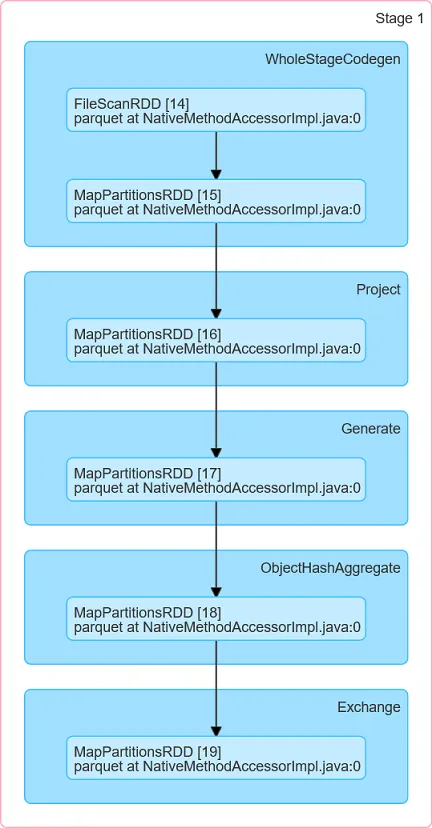
DAG:
当执行程序用尽其内存时,数据溢出会发生。而洗牌溢出(内存)是在我们将其溢出时内存中数据的反序列化形式的大小。
我正在本地运行spark,并将spark driver memory设置为10g。
如果我的理解是正确的,那么如果groupBy操作需要超过10GB的执行内存,则必须将数据溢出到磁盘上。
假设一个groupBy操作需要12GB内存,由于驱动器内存设置为10GB,它必须将近2GB的数据溢出到磁盘上,因此Shuffle Spill(Disk)应该是2GB,Shuffle spill(memory)应该是剩余的10GB,因为Shuffle spill(memory)是溢出时内存中数据的大小。
如果我的理解是正确的,那么Shuffle spill(memory)<= Executor memory。在我的情况下,它是驱动器内存,因为我正在本地运行spark。
但似乎我漏掉了什么,下面是来自spark ui的值。
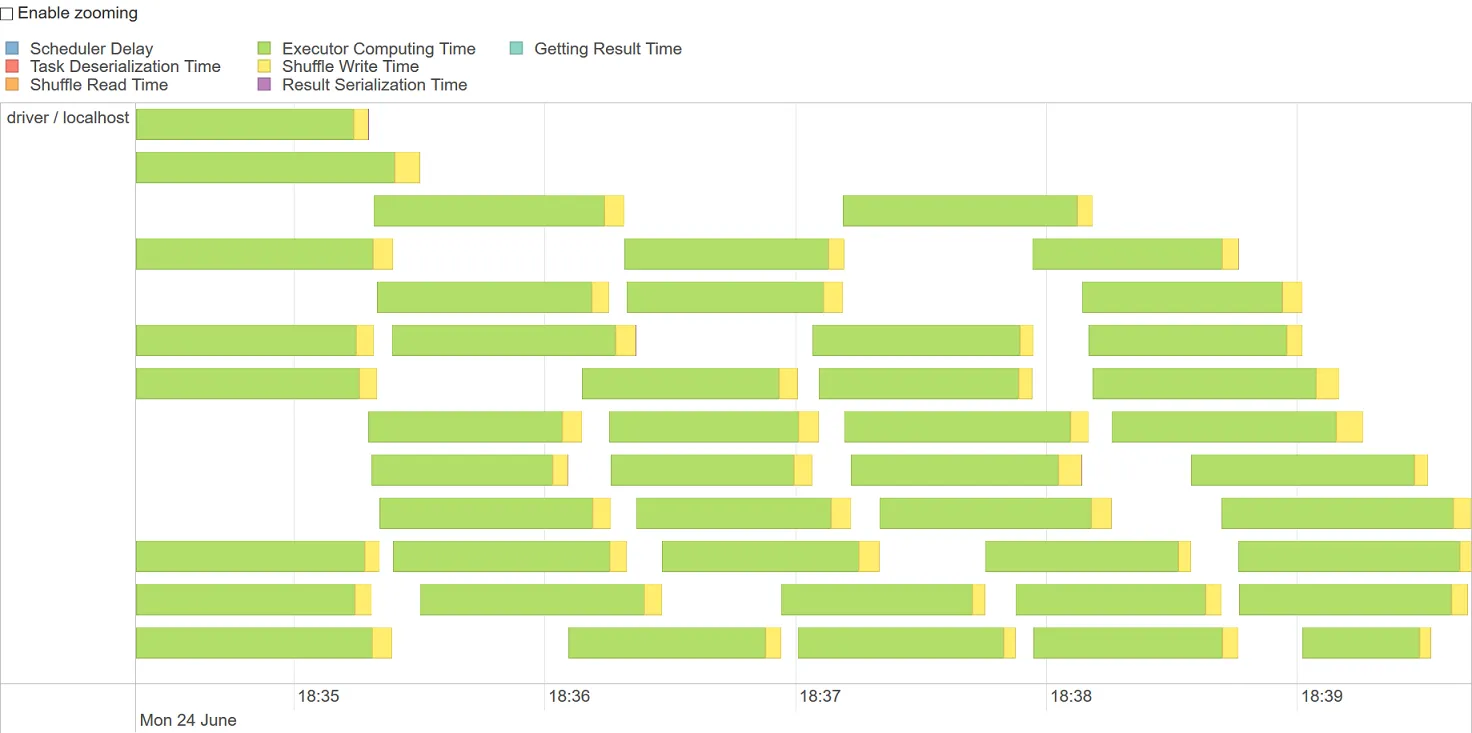
Total Time Across All Tasks: 41 min
Locality Level Summary: Process local: 45
Input Size / Records: 1428.1 MB / 42783987
Shuffle Write: 3.8 GB / 23391365
Shuffle Spill (Memory): 26.7 GB
Shuffle Spill (Disk): 2.1 GB
即使我将Spark驱动程序内存设置为
10g,但为什么内存洗牌溢出量会超过分配给驱动程序的内存。我观察到Windows任务管理器中的内存消耗在作业运行时从未超过
10.5GB,那么内存洗牌溢出(Memory Shuffle Spill)可能达到26.7 GB。DAG:
这是我正在尝试运行的代码(解决我的先前问题的解决方案)。