我正在对我在YARN上运行的Spark作业进行一些内存调优,并且我注意到不同的设置会产生不同的结果并影响Spark作业运行的结果。然而,我感到困惑,不完全理解为什么会发生这种情况,如果有人能为我提供一些指导和解释,我将不胜感激。
我将提供一些背景信息并发布我的问题并描述下面我经历过的情况。
我的环境设置如下:
- 每个节点20G内存,20个VCores(总共3个节点)
- Hadoop 2.6.0
- Spark 1.4.0
我的代码递归地过滤RDD以使其更小(作为算法的一部分删除示例),然后执行mapToPair并收集结果并将其保存在列表中。
问题
为什么仅增加执行器内存时第二种情况会抛出不同的错误并且作业运行时间较长?这两种错误是否有某种联系?
第三种和第四种情况都成功了,我明白这是因为我提供了更多的内存来解决内存问题。但是,在第三种情况下,
spark.driver.memory + spark.yarn.driver.memoryOverhead = YARN将创建的JVM内存
= 11g +(driverMemory * 0.07,最小为384m) = 11g + 1.154g = 12.154g
因此,从公式中,我可以看到我的作业需要 MEMORY_TOTAL 大约为12.154g 才能成功运行,这解释了为什么我需要10g以上的驱动器内存设置。
但是对于第四种情况,
spark.driver.memory + spark.yarn.driver.memoryOverhead = YARN将创建的JVM内存
= 2 + (driverMemory * 0.07, 至少为 384m) = 2g + 0.524g = 2.524g
似乎仅通过增加1024(1g)的内存开销,即可使具有仅2g驱动程序内存的作业成功运行,而 MEMORY_TOTAL 仅为2.524g !然而,如果没有增加内存开销的配置,则小于11g的驱动程序内存会失败,但是这不合理的,这就是我困惑的原因。
为什么增加内存开销(针对驱动程序和执行者)可以让我的作业成功完成,同时 MEMORY_TOTAL(12.154g vs 2.524g) 更低?我是否错过了一些其他内部工作?
第一种情况
/bin/spark-submit --class <class name> --master yarn-cluster --driver-memory 7g --executor-memory 1g --num-executors 3 --executor-cores 1 --jars <jar file>
如果我使用小于11g的任何驱动程序内存运行程序,则会出现下面的错误,这是SparkContext停止或类似错误(在停止SparkContext上调用的方法)。根据我收集的信息,这与内存不足有关。
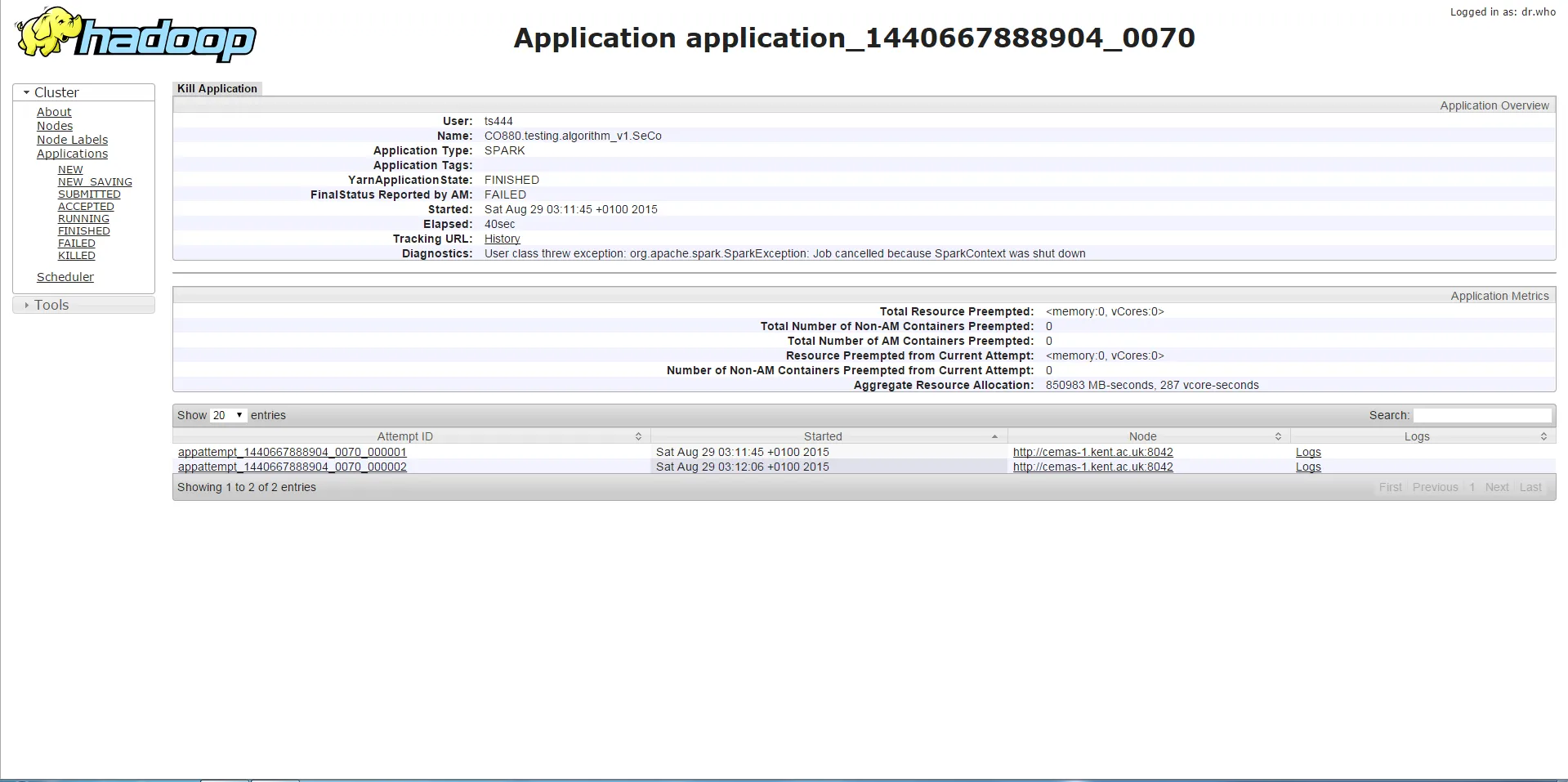
第二种情况
/bin/spark-submit --class <class name> --master yarn-cluster --driver-memory 7g --executor-memory 3g --num-executors 3 --executor-cores 1 --jars <jar file>
如果我使用相同的驱动程序内存但更高的执行器内存运行程序,则作业运行时间较长(约3-4分钟),然后它将遇到与先前不同的错误,该错误是容器请求/使用的内存超过允许的限制,因此被杀死。尽管执行器内存增加了,但这个错误发生了,而不是第一种情况下的错误。
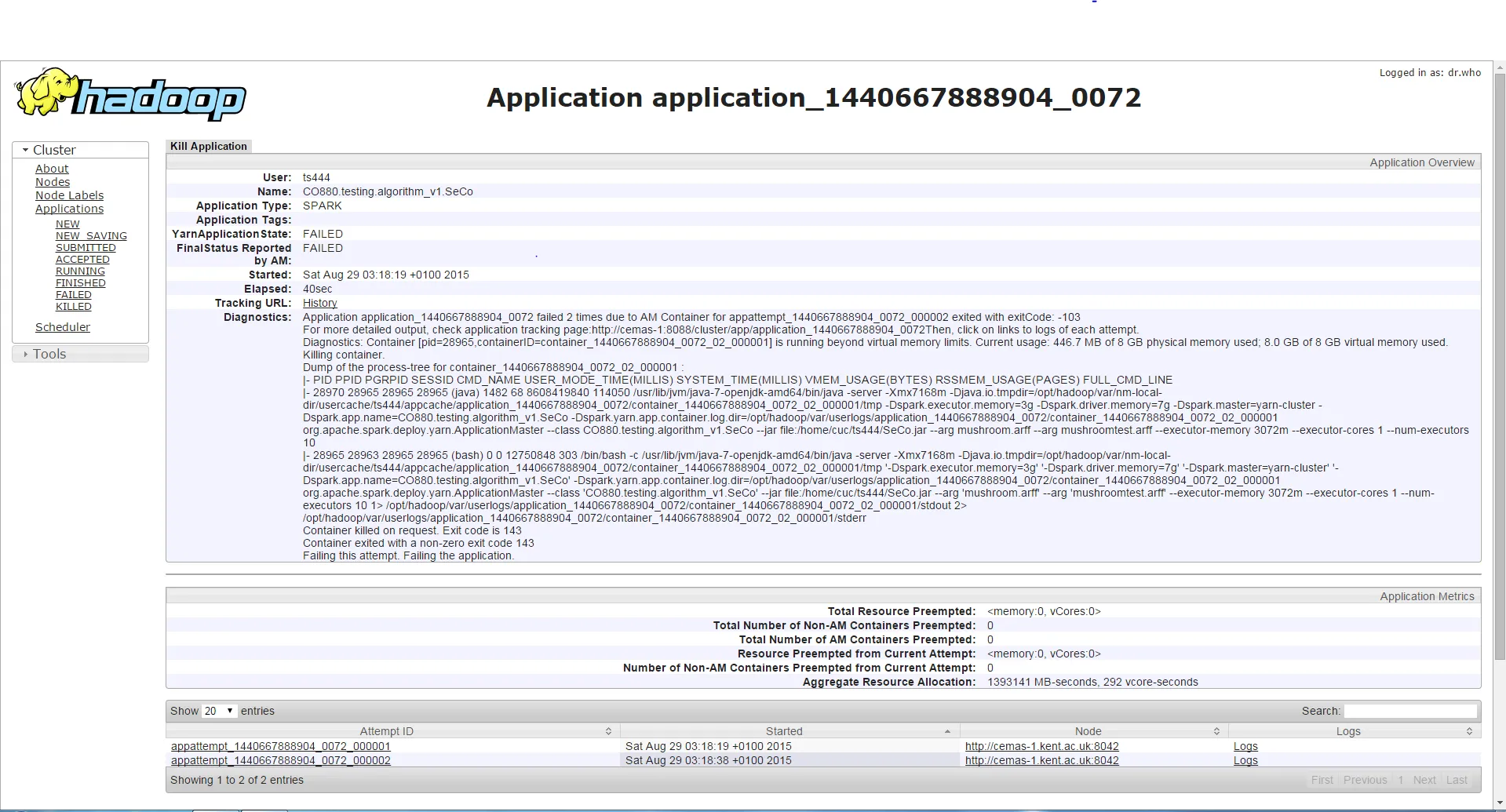
第三种情况
/bin/spark-submit --class <class name> --master yarn-cluster --driver-memory 11g --executor-memory 1g --num-executors 3 --executor-cores 1 --jars <jar file>
任何驱动程序内存大于10g的设置都将导致作业能够成功运行。
第四种情况
/bin/spark-submit --class <class name> --master yarn-cluster --driver-memory 2g --executor-memory 1g --conf spark.yarn.executor.memoryOverhead=1024 --conf spark.yarn.driver.memoryOverhead=1024 --num-executors 3 --executor-cores 1 --jars <jar file>
使用这个设置(驱动程序内存2g和执行器内存1g,但增加驱动程序内存开销(1g)和执行器内存开销(1g)),作业将成功运行。
非常感谢您的帮助,这将有助于我更好地理解Spark。提前感谢您的回复。