我正在学习Spark,并且关于作业调度和shuffle依赖有一个问题。这是我找到的DAG 链接在此:
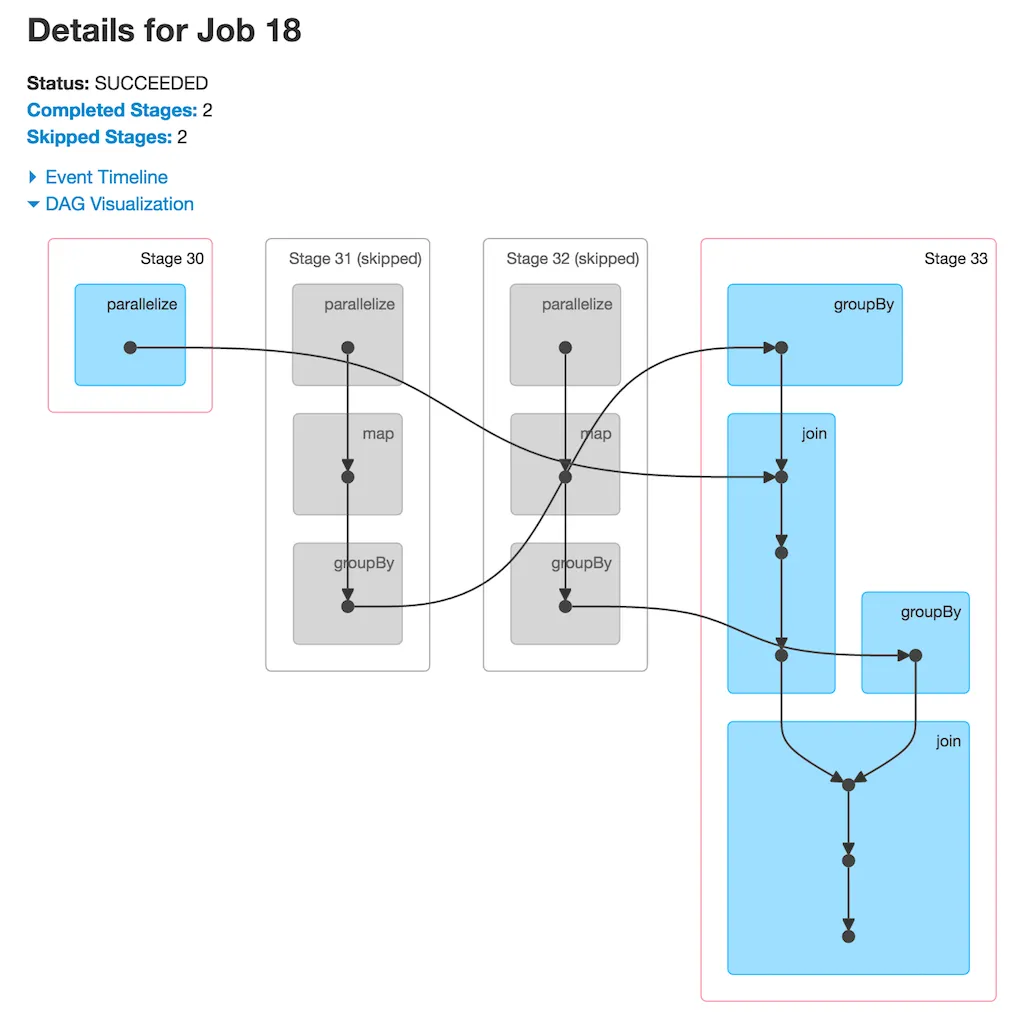
如我们所见,在阶段33中,我们有多个操作:groupBy、join、groupBy、join。问题是,我不太明白为什么两个groupBy操作被放入同一阶段?我认为groupBy需要shuffle,因此DAGScheduler应将Stage 33拆分成包含单个groupBy和join的2个阶段。