我对R语言中
使用来自
我一直无法确定这种行为的来源。虽然这可能读起来像一个错误报告,但我的问题是:
1.为什么会发生这种情况?我一直在尝试跟进
2.这是否是某种打算中的行为,如果是,我可以在哪里了解更多信息?
lm函数和相关的predict.lm函数的某些异常行为感兴趣。基础包splines提供了bs函数来生成b样条展开式,然后可以使用多功能线性模型拟合函数lm来拟合样条模型。
lm和predict.lm函数具有许多内置便利功能,利用公式和项。如果将bs()调用嵌套在lm调用中,则用户可以向predict提供单变量数据,这些数据将自动扩展为适当的b样条基础。然后像往常一样预测这个扩展的数据矩阵。library(splines)
x <- sort(runif(50, 0, 10))
y <- x^2
splineModel <- lm(y ~ bs(x, y, degree = 3, knots = c(3, 6)))
newData <- data.frame(x = 4)
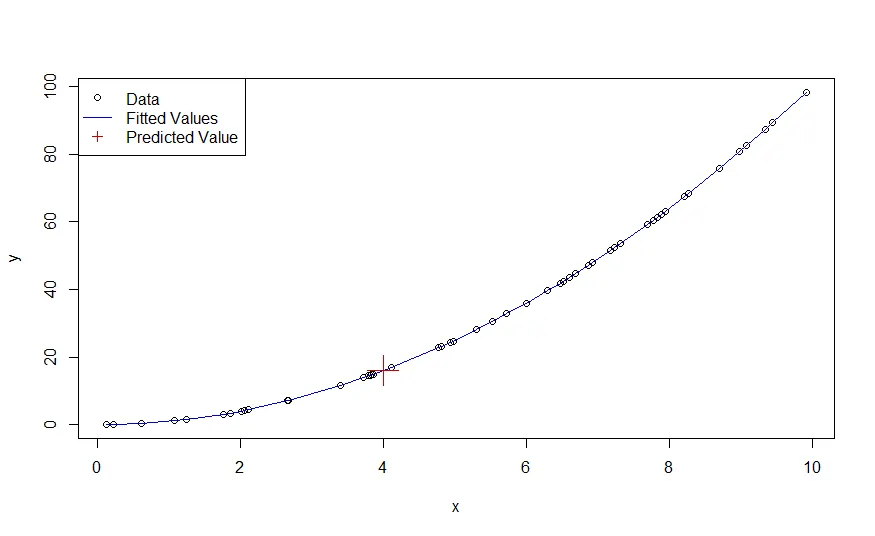
prediction <- predict(splineModel, newData) # 16
plot(x, y)
lines(x, splineModel$fitted.values, col = 'blue3')
points(newData$x, prediction, pch = 3, cex = 3, col = 'red3')
legend("topleft", legend = c("Data", "Fitted Values", "Predicted Value"),
pch = c(1, NA, 3), col = c('black', 'blue3', 'red3'), lty = c(NA, 1, NA))
正如我们所看到的,这个工作完美:
::运算符明确指示bs函数从splines包的命名空间中导出时,奇怪的事情发生了。以下代码片段除了这个更改外完全相同:library(splines)
x <- sort(runif(50, 0, 10))
y <- x^2
splineModel <- lm(y ~ splines::bs(x, y, degree = 3, knots = c(3, 6)))
newData <- data.frame(x = 4)
prediction <- predict(splineModel, newData) # 6.40171
plot(x, y)
lines(x, splineModel$fitted.values, col = 'blue3')
points(newData$x, prediction, pch = 3, cex = 3, col = 'red3')
legend("topleft", legend = c("Data", "Fitted Values", "Predicted Value"),
pch = c(1, NA, 3), col = c('black', 'blue3', 'red3'), lty = c(NA, 1, NA))
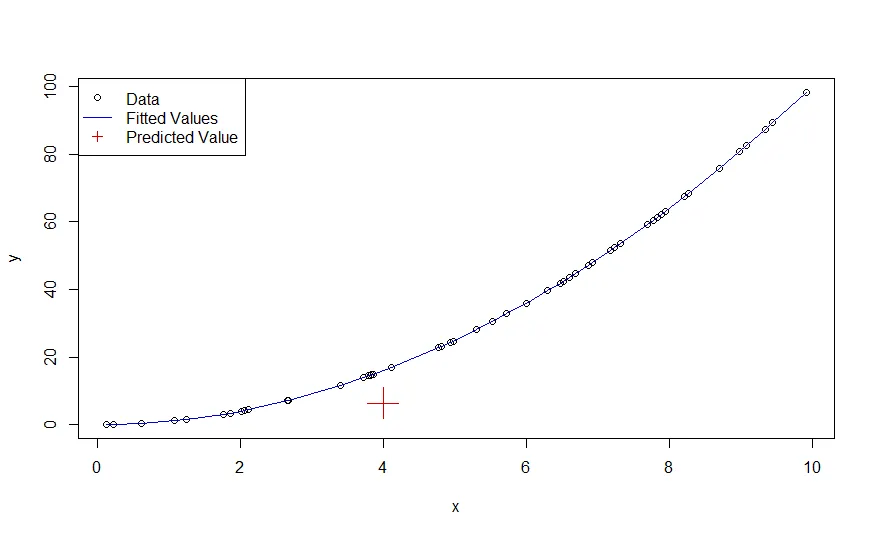
library附加splines软件包,则第二个片段将产生完全相同的结果。我无法想象其他情况下在已加载软件包上使用::运算符会改变程序行为。使用来自
splines的其他函数(如自然样条基础实现ns)会导致相同的行为。有趣的是,两种情况下的“y hat”或拟合值都是合理的,并且相互匹配。就我所知,除了属性名称之外,拟合模型对象是相同的。我一直无法确定这种行为的来源。虽然这可能读起来像一个错误报告,但我的问题是:
1.为什么会发生这种情况?我一直在尝试跟进
predict.lm,但无法确定发散发生的位置。2.这是否是某种打算中的行为,如果是,我可以在哪里了解更多信息?