MATLAB中的Tree类
我正在MATLAB中实现一种树形数据结构。添加新的子节点到树中,分配和更新与节点相关的数据值是我期望执行的典型操作。每个节点都有相同类型的data与之关联。对于我来说,删除节点并不是必需的。到目前为止,我已经决定采用从handle类继承的类实现,以便能够将引用传递给将修改树的函数。
编辑:12月2日
首先,感谢所有评论和答案中的建议。它们已经帮助我改进了我的树类。
有人建议尝试在R2015b中引入的digraph。我还没有探索过这个功能,但是由于它不能像从handle类继承的类那样作为引用参数工作,因此我有点怀疑它在我的应用程序中将如何工作。此时,对于如何使用自定义data来处理节点和边仍不清楚。
编辑:(12月3日)有关主要应用程序MCTS的更多信息
最初,我认为主要应用程序的细节只是边缘兴趣,但是自从阅读了评论和@FirefoxMetzger的答案以来,我意识到它具有重要的影响。
我正在实现一种Monte Carlo树搜索算法。搜索树以迭代方式进行探索和扩展。Wikipedia提供了该过程的良好图形概述: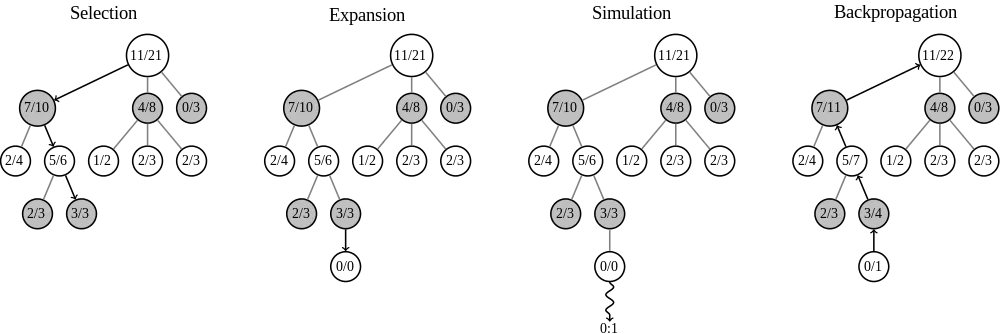
在我的应用程序中,我执行大量的搜索迭代。在每个搜索迭代中,我从根开始遍历当前树,直到叶节点,然后通过添加新节点扩展树,并重复此过程。由于该方法基于随机抽样,在每次迭代开始时,我不知道我将在每次迭代中完成哪个叶节点。相反,这是由当前树中节点的data和随机样本的结果共同确定的。我访问的任何节点都会更新其data。
示例:我在节点n,它有几个子节点。我需要访问每个孩子的数据,并绘制一个随机样本来确定下一步搜索哪个孩子。重复此过程,直到到达叶子节点。实际上,我通过在根上调用search函数来实现这一点,该函数将决定下一个要展开的子节点,递归地调用search该节点,等等,最后一旦到达叶子节点就返回一个值。返回递归函数时使用此值以更新搜索迭代期间访问的节点的data。
树可能非常不平衡,某些分支是非常长的节点链,而其他分支在根级别之后很快终止并且不再展开。
当前实现
以下是我的当前实现示例,其中包括添加节点、查询深度或树中节点数量等成员函数的示例。
classdef stree < handle
% A class for a tree object that acts like a reference
% parameter.
% The tree can be traversed in both directions by using the parent
% and children information.
% New nodes can be added to the tree. The object will automatically
% keep track of the number of nodes in the tree and increment the
% storage space as necessary.
properties (SetAccess = private)
% Hold the data at each node
Node = { [] };
% Index of the parent node. The root of the tree as a parent index
% equal to 0.
Parent = 0;
num_nodes = 0;
size_increment = 1;
maxSize = 1;
end
methods
function [obj, root_ID] = stree(data, init_siz)
% New object with only root content, with specified initial
% size
obj.Node = repmat({ data },init_siz,1);
obj.Parent = zeros(init_siz,1);
root_ID = 1;
obj.num_nodes = 1;
obj.size_increment = init_siz;
obj.maxSize = numel(obj.Parent);
end
function ID = addnode(obj, parent, data)
% Add child node to specified parent
if obj.num_nodes < obj.maxSize
% still have room for data
idx = obj.num_nodes + 1;
obj.Node{idx} = data;
obj.Parent(idx) = parent;
obj.num_nodes = idx;
else
% all preallocated elements are in use, reserve more memory
obj.Node = [
obj.Node
repmat({data},obj.size_increment,1)
];
obj.Parent = [
obj.Parent
parent
zeros(obj.size_increment-1,1)];
obj.num_nodes = obj.num_nodes + 1;
obj.maxSize = numel(obj.Parent);
end
ID = obj.num_nodes;
end
function content = get(obj, ID)
%% GET Return the contents of the given node IDs.
content = [obj.Node{ID}];
end
function obj = set(obj, ID, content)
%% SET Set the content of given node ID and return the modifed tree.
obj.Node{ID} = content;
end
function IDs = getchildren(obj, ID)
% GETCHILDREN Return the list of ID of the children of the given node ID.
% The list is returned as a line vector.
IDs = find( obj.Parent(1:obj.num_nodes) == ID );
IDs = IDs';
end
function n = nnodes(obj)
% NNODES Return the number of nodes in the tree.
% Equal to root + those whose parent is not root.
n = 1 + sum(obj.Parent(1:obj.num_nodes) ~= 0);
assert( obj.num_nodes == n);
end
function flag = isleaf(obj, ID)
% ISLEAF Return true if given ID matches a leaf node.
% A leaf node is a node that has no children.
flag = ~any( obj.Parent(1:obj.num_nodes) == ID );
end
function depth = depth(obj,ID)
% DEPTH return depth of tree under ID. If ID is not given, use
% root.
if nargin == 1
ID = 0;
end
if obj.isleaf(ID)
depth = 0;
else
children = obj.getchildren(ID);
NC = numel(children);
d = 0; % Depth from here on out
for k = 1:NC
d = max(d, obj.depth(children(k)));
end
depth = 1 + d;
end
end
end
end
然而,有时候性能较慢,树的操作占据了大部分计算时间。有哪些具体的方法可以使实现更加高效?如果存在性能提升,甚至可以将实现更改为其他类型而不是“handle”继承类型。
当前实现的分析结果
由于向树中添加新节点是最典型的操作之一(以及更新节点的data),我对此进行了一些分析。
我使用以下基准代码在Nd=6, Ns=10下运行了分析器。
function T = benchmark(Nd, Ns)
% Tree benchmark. Nd: tree depth, Ns: number of nodes per layer
% Initialize tree
T = stree(rand, 10000);
add_layers(1, Nd);
function add_layers(node_id, num_layers)
if num_layers == 0
return;
end
child_id = zeros(Ns,1);
for s = 1:Ns
% add child to current node
child_id(s) = T.addnode(node_id, rand);
% recursively increase depth under child_id(s)
add_layers(child_id(s), num_layers-1);
end
end
end
分析器的结果:
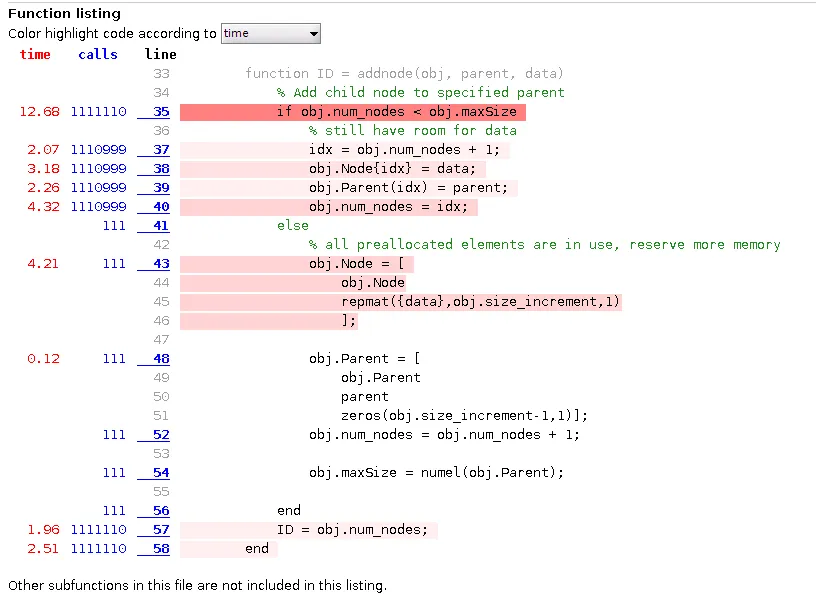
R2015b 性能
发现 R2015b 改进了 MATLAB 的面向对象编程功能的性能。我重做了上述基准测试,确实观察到性能提高:
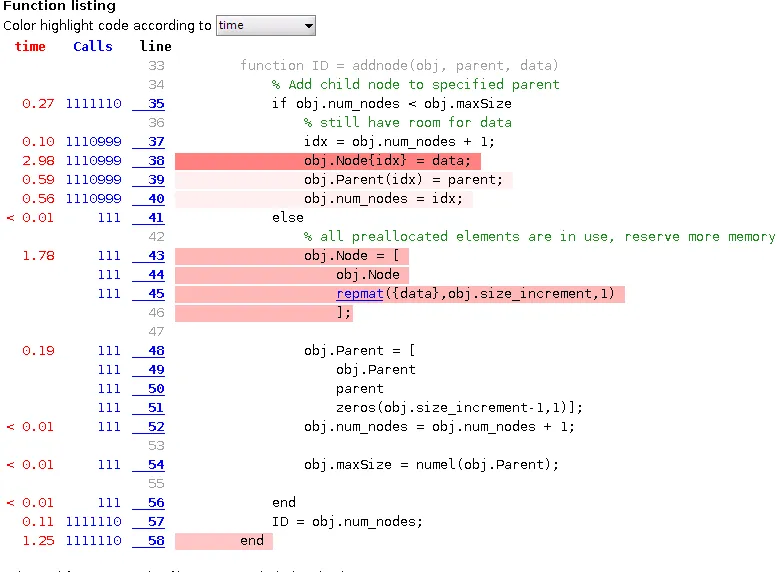
所以这已经是一个好消息,当然如果有更进一步的改进就更好了 ;)
以不同的方式预留内存
在评论中还建议使用
obj.Node = [obj.Node; data; cell(obj.size_increment - 1,1)];
为了比当前使用repmat的方法更好地保留内存,这样可以稍微提高性能。需要注意的是,我的基准代码是针对虚拟数据的,实际上由于实际数据更加复杂,因此这可能会有所帮助。以下是分析器的结果:
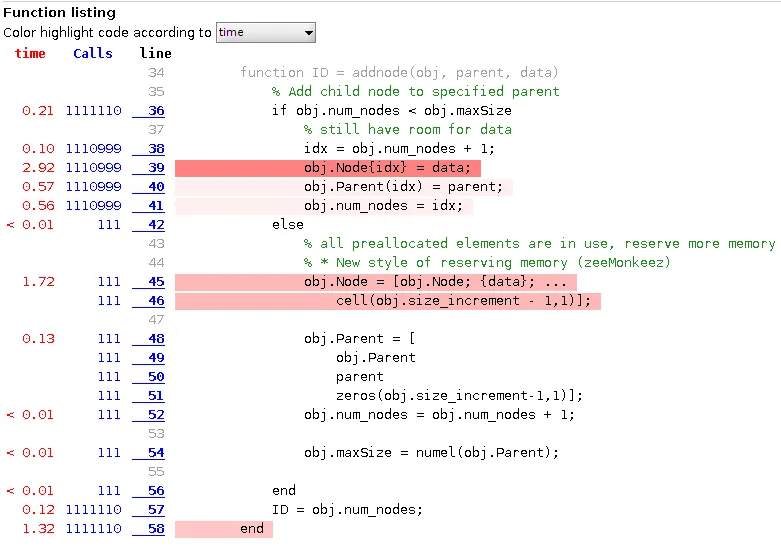
关于进一步提高性能的问题
- 也许有一种更有效的方法来维护树的内存?不幸的是,我通常不知道树中会有多少个节点。
- 向树中添加新节点和修改现有节点的数据是我在树上执行的最典型操作。到目前为止,它们实际上占用了主应用程序大部分处理时间。任何这些功能的改进都将受到欢迎。
作为最后的说明,我希望保持实现纯MATLAB。但是,如MEX或使用一些集成的Java功能等选项也是可以接受的。
profiler可以在性能方面对你的代码进行很多揭示。运行一次,看看代码在哪里异常缓慢,它会给你一个指引,告诉你从哪里开始改进。 - Adriaanrepmat来分配节点数据可能会增加很多开销。为什么不使用obj.Node = [obj.Node; data; cell(obj.size_increment - 1,1)];进行初始化呢? - zeeMonkeezdigraph将节点和边都实现为 MATLAB 表格,因此将额外数据存储到节点中只需要添加列即可。如果需要以面向对象的方式处理每个节点本身的数据,则可以在列中存储对象句柄。对于树本身的面向对象遍历,最清晰的方法可能是子类化digraph本身。 - Will