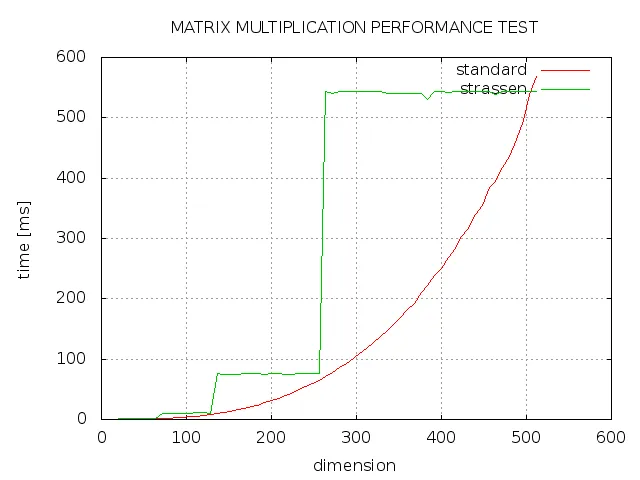
我试图使用C ++实现 Strassen算法进行矩阵乘法,但结果并非我所期望的。如您所见,Strassen始终需要比标准实现更多的时间,并且仅在维数为2的幂时才与标准实现一样快。出了什么问题?
matrix mult_strassen(matrix a, matrix b) {
if (a.dim() <= cut)
return mult_std(a, b);
matrix a11 = get_part(0, 0, a);
matrix a12 = get_part(0, 1, a);
matrix a21 = get_part(1, 0, a);
matrix a22 = get_part(1, 1, a);
matrix b11 = get_part(0, 0, b);
matrix b12 = get_part(0, 1, b);
matrix b21 = get_part(1, 0, b);
matrix b22 = get_part(1, 1, b);
matrix m1 = mult_strassen(a11 + a22, b11 + b22);
matrix m2 = mult_strassen(a21 + a22, b11);
matrix m3 = mult_strassen(a11, b12 - b22);
matrix m4 = mult_strassen(a22, b21 - b11);
matrix m5 = mult_strassen(a11 + a12, b22);
matrix m6 = mult_strassen(a21 - a11, b11 + b12);
matrix m7 = mult_strassen(a12 - a22, b21 + b22);
matrix c(a.dim(), false, true);
set_part(0, 0, &c, m1 + m4 - m5 + m7);
set_part(0, 1, &c, m3 + m5);
set_part(1, 0, &c, m2 + m4);
set_part(1, 1, &c, m1 - m2 + m3 + m6);
return c;
}
程序
matrix.h http://pastebin.com/TYFYCTY7
matrix.cpp http://pastebin.com/wYADLJ8Y
main.cpp http://pastebin.com/48BSqGJr
使用 g++ 编译 main.cpp 和 matrix.cpp,并将输出保存为 matrix,使用 -O3 优化选项。