我曾经用C++、Python和Java编写程序来进行矩阵乘法,并测试了它们在两个2000 x 2000的矩阵相乘方面的速度(参见文章)。标准的ikj-implentation实现如下图所示: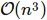 ,其用时如下:
,其用时如下:
现在,我已经按照维基百科上的方法,用Python和C++实现了Strassen算法,其中Python的实现如下图所示: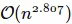 ,它们的用时如下:
,它们的用时如下:
为什么Strassen矩阵乘法比标准矩阵乘法慢得多?
可能的原因:
- 某些缓存效应
- 实现问题:
- 错误(结果为2000 x 2000的矩阵是正确的)
- null-multiplication(对于 2000 x 2000 -> 2048 x 2048 不应该那么重要)
这尤其令人惊讶,因为它似乎与其他人的经验相矛盾:
- 为什么我的 Strassen 矩阵乘法器如此快?
- 矩阵乘法:Strassen vs. Standard - 对他来说 Strassen 更慢,但至少在同一数量级。
编辑:在我这种情况下 Strassen 矩阵乘法较慢的原因是:
- 我将其全部递归化(请参见 tam)
- 我有两个函数
strassen和strassenRecursive。第一个如果需要则将矩阵调整大小到二的幂,并调用第二个函数。但是strassenRecursive没有递归调用自身,而是调用了strassen。