通常您会收到一个整数值的向量,表示您的标签(也称为类别),例如
[2; 1; 3; 3; 2]
如果您想要对这个向量进行热编码,可以将标签向量中每行的值所示的列表示为1,例如:
[0 1 0;
1 0 0;
0 0 1;
0 0 1;
0 1 0]
通常您会收到一个整数值的向量,表示您的标签(也称为类别),例如
[2; 1; 3; 3; 2]
如果您想要对这个向量进行热编码,可以将标签向量中每行的值所示的列表示为1,例如:
[0 1 0;
1 0 0;
0 0 1;
0 0 1;
0 1 0]
bsxfun结合eq来实现相同的功能。虽然您的eye解决方案可能有效,但是随着X中唯一值数量的增加,您的内存使用会呈二次增长趋势。Y = bsxfun(@eq, X(:), 1:max(X));
如果您喜欢,也可以将其作为匿名函数:
hotone = @(X)bsxfun(@eq, X(:), 1:max(X));
如果您使用的是Octave(或MATLAB版本R2016b及更高版本),您可以利用自动广播功能,按照@Tasos所建议的简单地执行以下操作。
Y = X == 1:max(X);
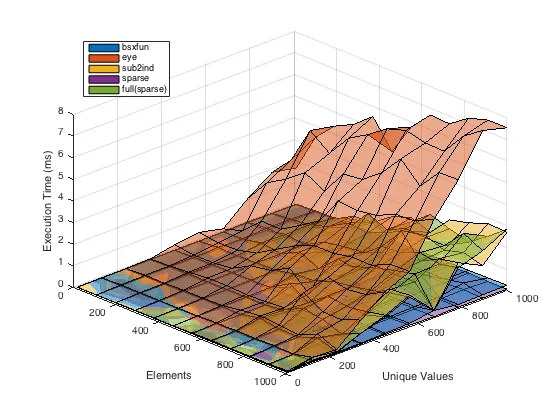
这里是一个快速基准测试,展示了在X上有不同数量元素和不同数量唯一值的情况下各种答案的性能。
function benchit()
nUnique = round(linspace(10, 1000, 10));
nElements = round(linspace(10, 1000, 12));
times1 = zeros(numel(nUnique), numel(nElements));
times2 = zeros(numel(nUnique), numel(nElements));
times3 = zeros(numel(nUnique), numel(nElements));
times4 = zeros(numel(nUnique), numel(nElements));
times5 = zeros(numel(nUnique), numel(nElements));
for m = 1:numel(nUnique)
for n = 1:numel(nElements)
X = randi(nUnique(m), nElements(n), 1);
times1(m,n) = timeit(@()bsxfunApproach(X));
X = randi(nUnique(m), nElements(n), 1);
times2(m,n) = timeit(@()eyeApproach(X));
X = randi(nUnique(m), nElements(n), 1);
times3(m,n) = timeit(@()sub2indApproach(X));
X = randi(nUnique(m), nElements(n), 1);
times4(m,n) = timeit(@()sparseApproach(X));
X = randi(nUnique(m), nElements(n), 1);
times5(m,n) = timeit(@()sparseFullApproach(X));
end
end
colors = get(0, 'defaultaxescolororder');
figure;
surf(nElements, nUnique, times1 * 1000, 'FaceColor', colors(1,:), 'FaceAlpha', 0.5);
hold on
surf(nElements, nUnique, times2 * 1000, 'FaceColor', colors(2,:), 'FaceAlpha', 0.5);
surf(nElements, nUnique, times3 * 1000, 'FaceColor', colors(3,:), 'FaceAlpha', 0.5);
surf(nElements, nUnique, times4 * 1000, 'FaceColor', colors(4,:), 'FaceAlpha', 0.5);
surf(nElements, nUnique, times5 * 1000, 'FaceColor', colors(5,:), 'FaceAlpha', 0.5);
view([46.1000 34.8000])
grid on
xlabel('Elements')
ylabel('Unique Values')
zlabel('Execution Time (ms)')
legend({'bsxfun', 'eye', 'sub2ind', 'sparse', 'full(sparse)'}, 'Location', 'Northwest')
end
function Y = bsxfunApproach(X)
Y = bsxfun(@eq, X(:), 1:max(X));
end
function Y = eyeApproach(X)
tmp = eye(max(X));
Y = tmp(X, :);
end
function Y = sub2indApproach(X)
LinearIndices = sub2ind([length(X),max(X)], [1:length(X)]', X);
Y = zeros(length(X), max(X));
Y(LinearIndices) = 1;
end
function Y = sparseApproach(X)
Y = sparse(1:numel(X), X,1);
end
function Y = sparseFullApproach(X)
Y = full(sparse(1:numel(X), X,1));
end
如果您需要非稀疏输出,则bsxfun表现最佳,但如果您可以使用稀疏矩阵(无需转换为完整矩阵),那么这是最快速和最节省内存的选项。
X == 1:max(X)),这似乎比bsxfun更快。 - Tasos PapastylianouX = randi(3,5,1)
ans =
2
1
2
3
3
eye(max(X))(X,:)
hotone = @(v) eye(max(v))(v,:)
编辑:
尽管上述解决方案适用于Octave,但您需要对Matlab进行修改,方法如下
I = eye(max(X));
I(X,:)
Y = sparse(1:numel(X), X,1);
Y = full(sparse(1:numel(X), X,1));
我也来发一下sub2ind的解决方案,以满足你的好奇心 :)
但我更喜欢你的解决方案 :p
>> X = [2,1,2,3,3]'
>> LinearIndices = sub2ind([length(X),3], [1:length(X)]', X);
>> tmp = zeros(length(X), 3);
>> tmp(LinearIndices) = 1
tmp =
0 1 0
1 0 0
0 1 0
0 0 1
0 0 1
以防万一有人正在寻找2D情况(就像我一样):
X = [2 1; ...
3 3; ...
2 4]
Y = zeros(3,2,4)
for i = 1:4
Y(:,:,i) = ind2sub(X,X==i)
end
在第三个维度上给出一个独热编码的矩阵。