我有一个数据帧,长这样:
index value
0 1
1 1
2 2
3 3
4 2
5 1
6 1
我希望每个值都返回前一个较小值的索引,以及前一个“1”值的索引。如果值为1,则不需要它们(两个值都可以是
-1或其他值)。因此,我想要的是:
index value previous_smaller_index previous_1_index
0 1 -1 -1
1 1 -1 -1
2 2 1 1
3 3 2 1
4 2 1 1
5 1 -1 -1
6 1 -1 -1
我尝试使用滚动、累积函数等方法,但是无法弄清楚。欢迎任何帮助!
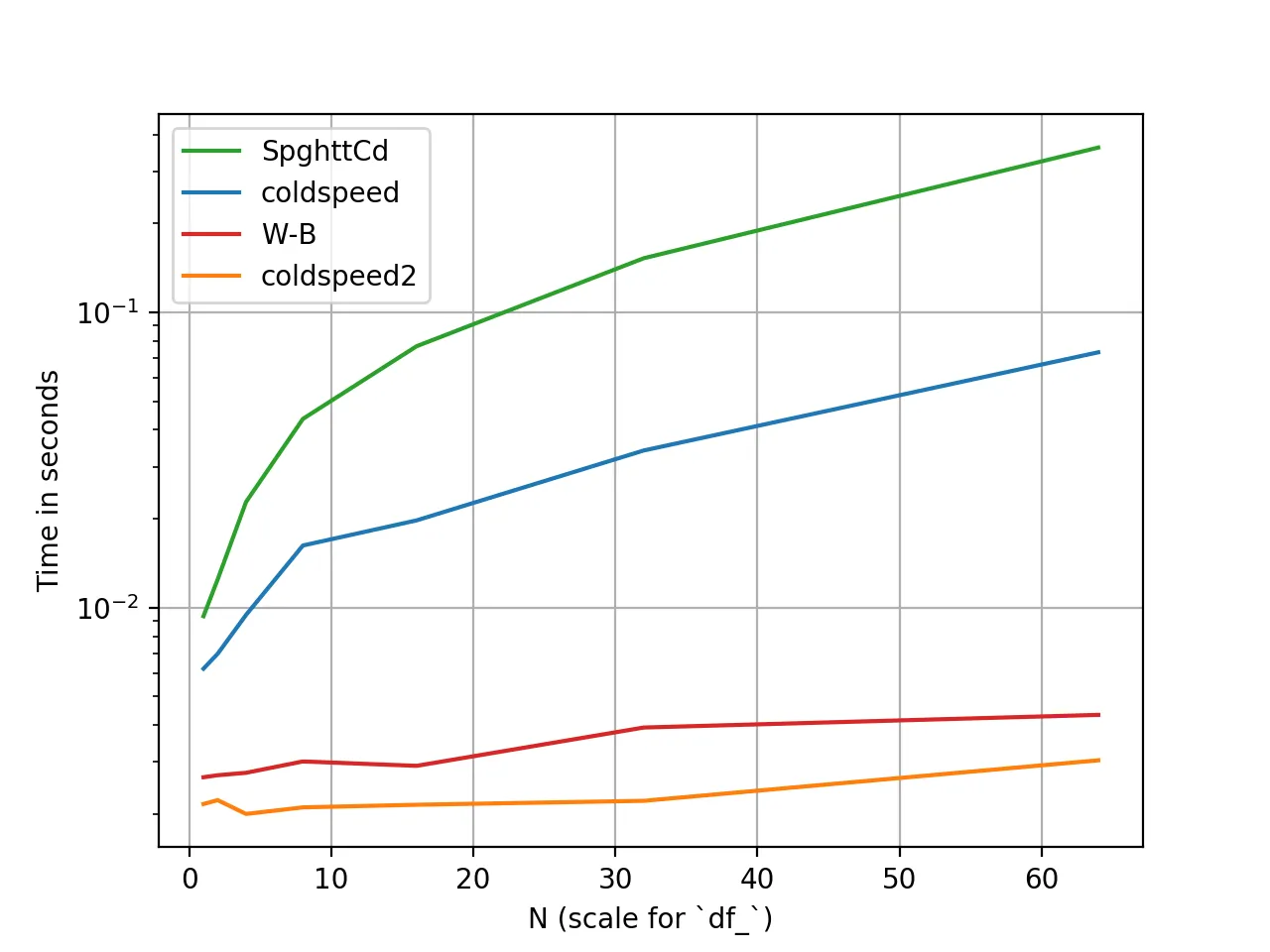
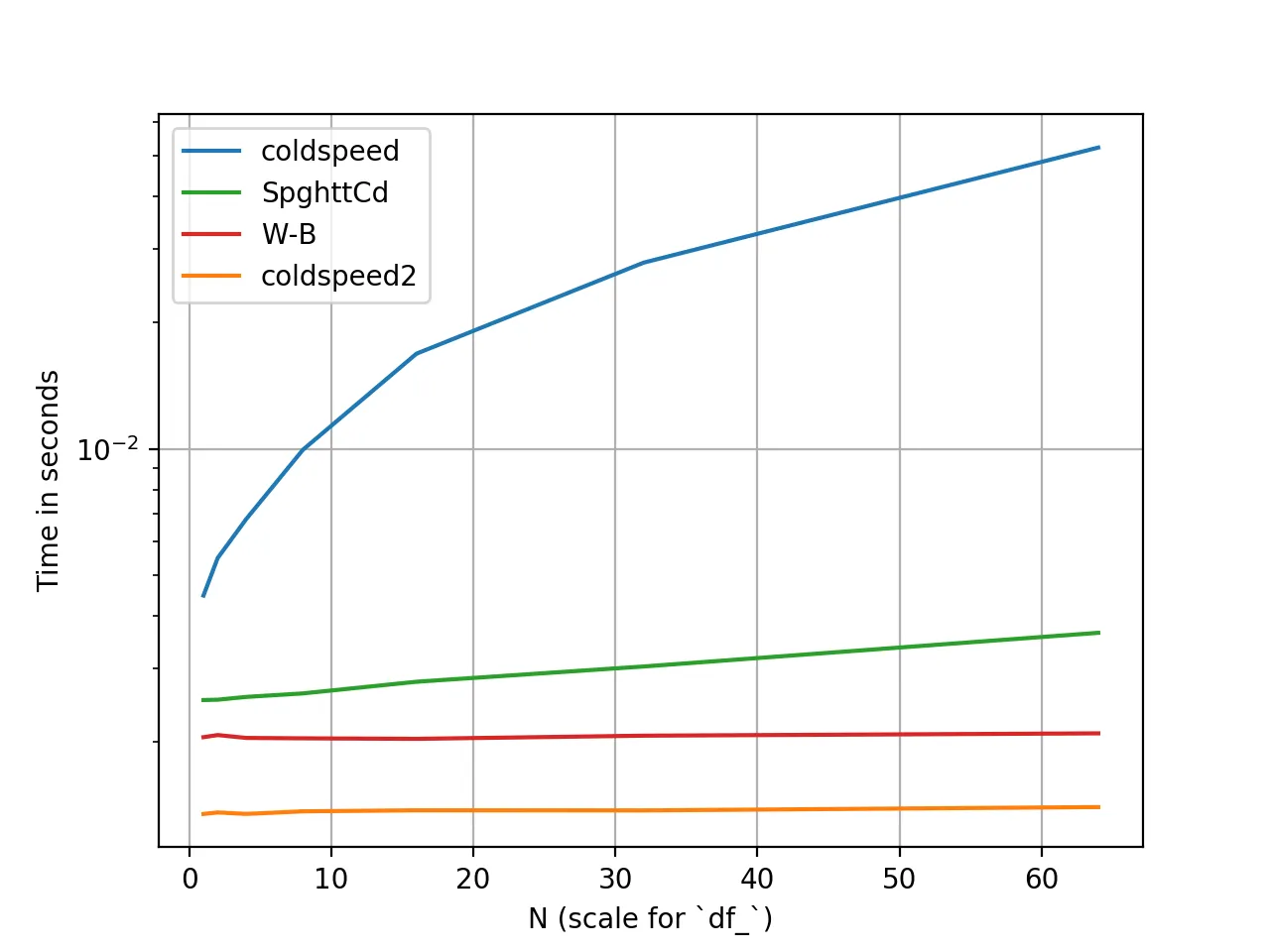
编辑: SpghttCd已经为“前1个”问题提供了一个不错的解决方案。我正在寻找一个漂亮的pandas一行代码解决“前小”问题。(当然,对于这两个问题,更好和更有效的解决方案都受到欢迎)