设置
为了演示的目的,让我们考虑这个数据框。
df = pd.DataFrame({'text':['a..b?!??', '%hgh&12','abc123!!!', '$$$1234']})
df
text
0 a..b?!??
1 %hgh&12
2 abc123!!!
3 $$$1234
以下按性能递增的顺序逐一列出备选方案:
str.replace
此选项用于将默认方法设为基准,以比较其他更高效的解决方法。
此方法使用 pandas 内置的 str.replace 函数来执行基于正则表达式的替换。
df['text'] = df['text'].str.replace(r'[^\w\s]+', '')
df
text
0 ab
1 hgh12
2 abc123
3 1234
这段代码非常容易编写,而且还很易读,但是运行速度较慢。
regex.sub
使用re库中的sub函数,预编译正则表达式模式以提高性能,并在列表推导式内调用regex.sub。如果可以节省一些内存,请先将df['text']转换为列表,这样您就可以获得小型性能提升。
import re
p = re.compile(r'[^\w\s]+')
df['text'] = [p.sub('', x) for x in df['text'].tolist()]
df
text
0 ab
1 hgh12
2 abc123
3 1234
注意:如果您的数据中包含NaN值,那么这个方法(以及下面介绍的方法)将无法使用。请参阅“其他注意事项”部分。
str.translate
Python的str.translate函数是用C实现的,因此非常快速。
它的工作原理如下:
- 首先,使用您选择的一个或多个字符的分隔符将所有字符串连接在一起,形成一个巨大的字符串。您必须使用一个您可以保证不会出现在数据中的字符/子字符串。
- 在大字符串上执行
str.translate,删除标点符号(从步骤1中排除的分隔符)。
- 在第1步使用的分隔符上拆分字符串。结果列表必须与您的初始列具有相同的长度。
在这个例子中,我们考虑管道分隔符|。如果您的数据包含管道,则必须选择另一个分隔符。
import string
punct = '!"#$%&\'()*+,-./:;<=>?@[\\]^_`{}~'
transtab = str.maketrans(dict.fromkeys(punct, ''))
df['text'] = '|'.join(df['text'].tolist()).translate(transtab).split('|')
df
text
0 ab
1 hgh12
2 abc123
3 1234
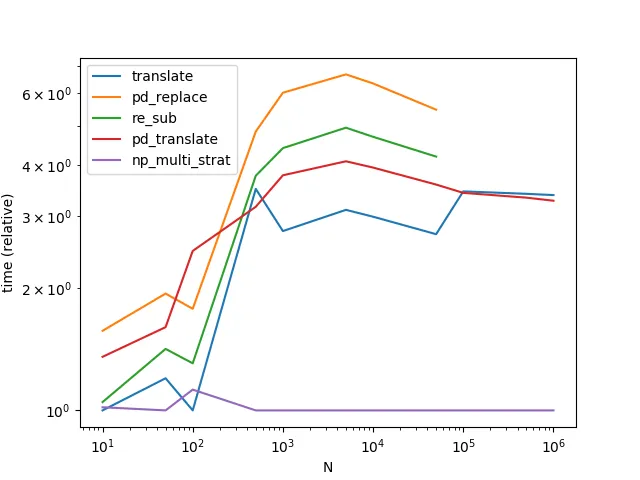
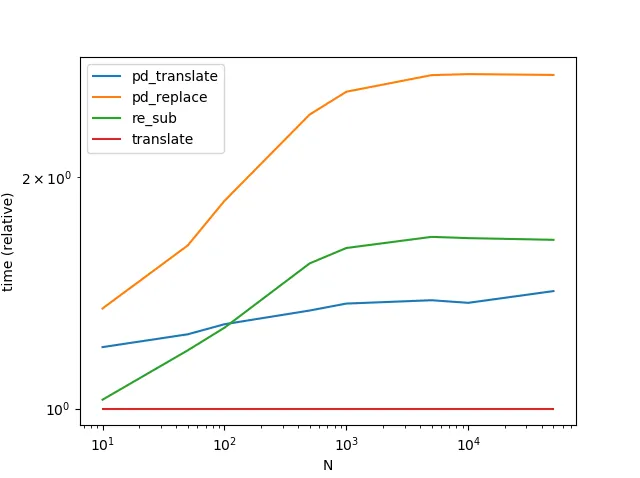
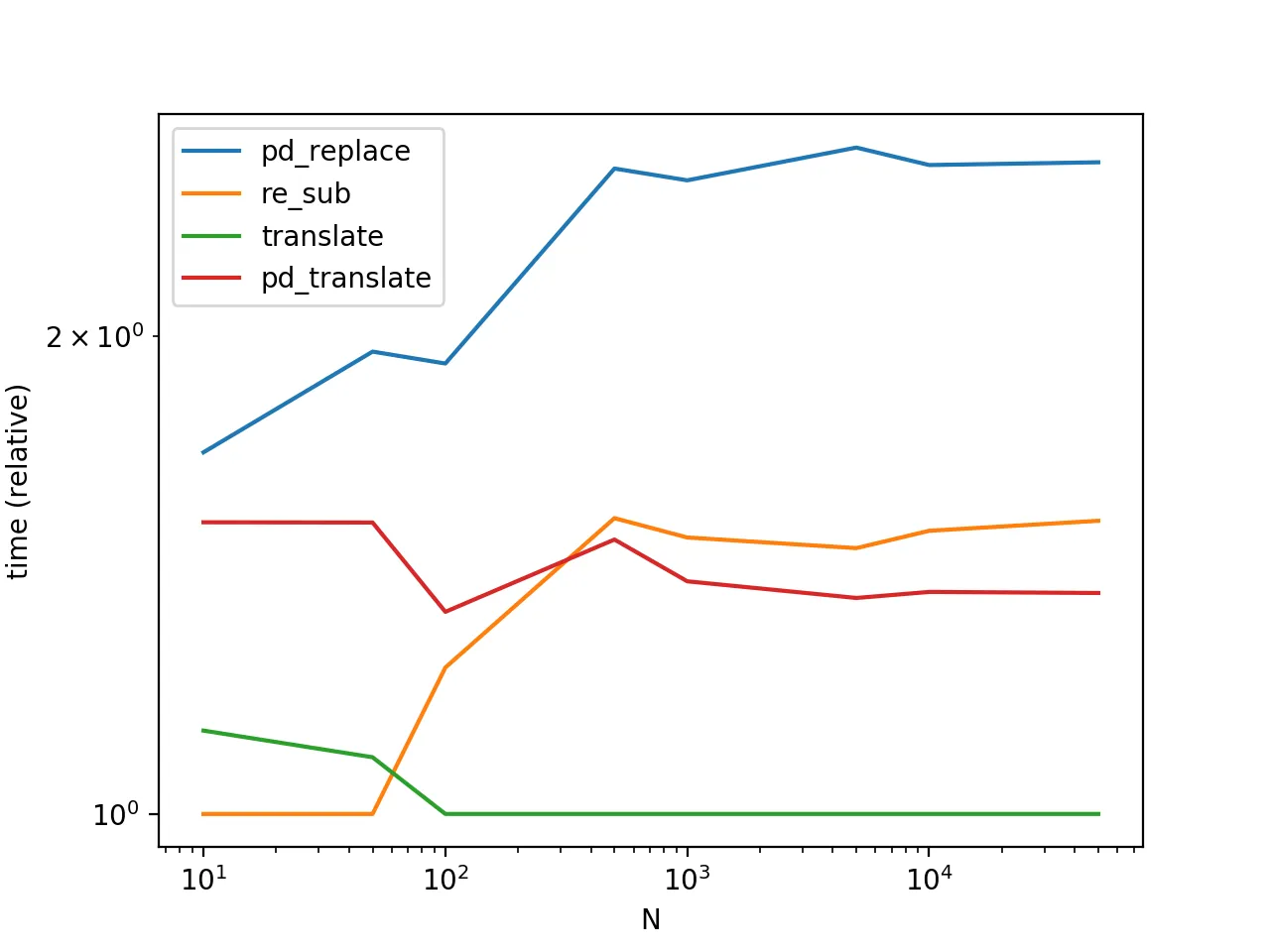
性能
str.translate 的性能是最好的。需要注意的是下面的图表还包括了另一种变体 Series.str.translate,出自于MaxU 的答案。
(有趣的是,我第二次重新运行时,结果与之前稍有不同。在第二次运行期间,似乎对于非常少量数据,re.sub 胜过了 str.translate。)
使用 translate 存在固有的风险(特别是自动化决定使用哪个分隔符的问题并不容易),但是这种折衷是值得冒险的。
其他考虑因素
使用列表推导式方法处理 NaNs; 需要注意的是,此方法(和下一个方法)只适用于您的数据没有NaNs的情况。当处理NaNs时,您需要确定非null值的索引并仅替换这些值。尝试像这样:
df = pd.DataFrame({'text': [
'a..b?!??', np.nan, '%hgh&12','abc123!!!', '$$$1234', np.nan]})
idx = np.flatnonzero(df['text'].notna())
col_idx = df.columns.get_loc('text')
df.iloc[idx,col_idx] = [
p.sub('', x) for x in df.iloc[idx,col_idx].tolist()]
df
text
0 ab
1 NaN
2 hgh12
3 abc123
4 1234
5 NaN
处理数据框:如果你正在处理包含需要替换每个列的数据框,那么程序很简单:
v = pd.Series(df.values.ravel())
df[:] = translate(v).values.reshape(df.shape)
或者,
v = df.stack()
v[:] = translate(v)
df = v.unstack()
注意,
translate函数在基准测试代码中定义。每种解决方案都有取舍,因此选择最适合您需求的解决方案将取决于您愿意牺牲什么。两个非常常见的考虑因素是性能(我们已经看到了)和内存使用情况。
str.translate是一种占用内存较多的解决方案,因此请谨慎使用。另一个考虑因素是正则表达式的复杂性。有时,您可能想删除任何非字母数字或空格的内容。其他情况下,您需要保留某些字符,例如连字符、冒号和句子终止符
[.!?]。明确指定这些字符会增加正则表达式的复杂度,这可能会影响这些解决方案的性能。确保在使用之前在自己的数据上进行测试并决定使用什么。最后,这种解决方案将删除Unicode字符。如果使用基于正则表达式的解决方案,则可能需要微调正则表达式,否则可以使用
str.translate。对于更大的N,要获得更高的性能,请查看
Paul Panzer的答案。附录:函数。
def pd_replace(df):
return df.assign(text=df['text'].str.replace(r'[^\w\s]+', ''))
def re_sub(df):
p = re.compile(r'[^\w\s]+')
return df.assign(text=[p.sub('', x) for x in df['text'].tolist()])
def translate(df):
punct = string.punctuation.replace('|', '')
transtab = str.maketrans(dict.fromkeys(punct, ''))
return df.assign(
text='|'.join(df['text'].tolist()).translate(transtab).split('|')
)
def pd_translate(df):
punct = string.punctuation.replace('|', '')
transtab = str.maketrans(dict.fromkeys(punct, ''))
return df.assign(text=df['text'].str.translate(transtab))
性能基准测试代码
from timeit import timeit
import pandas as pd
import matplotlib.pyplot as plt
res = pd.DataFrame(
index=['pd_replace', 're_sub', 'translate', 'pd_translate'],
columns=[10, 50, 100, 500, 1000, 5000, 10000, 50000],
dtype=float
)
for f in res.index:
for c in res.columns:
l = ['a..b?!??', '%hgh&12','abc123!!!', '$$$1234'] * c
df = pd.DataFrame({'text' : l})
stmt = '{}(df)'.format(f)
setp = 'from __main__ import df, {}'.format(f)
res.at[f, c] = timeit(stmt, setp, number=30)
ax = res.div(res.min()).T.plot(loglog=True)
ax.set_xlabel("N");
ax.set_ylabel("time (relative)");
plt.show()