我认为jterrace的答案可能是最好的方法,但这里还有另一种可能性。
def byte_offset(a):
"""Returns a 1-d array of the byte offset of every element in `a`.
Note that these will not in general be in order."""
stride_offset = np.ix_(*map(range,a.shape))
element_offset = sum(i*s for i, s in zip(stride_offset,a.strides))
element_offset = np.asarray(element_offset).ravel()
return np.concatenate([element_offset + x for x in range(a.itemsize)])
def share_memory(a, b):
"""Returns the number of shared bytes between arrays `a` and `b`."""
a_low, a_high = np.byte_bounds(a)
b_low, b_high = np.byte_bounds(b)
beg, end = max(a_low,b_low), min(a_high,b_high)
if end - beg > 0:
amem = a_low + byte_offset(a)
bmem = b_low + byte_offset(b)
return np.intersect1d(amem,bmem).size
else:
return 0
示例:
>>> a = np.arange(10)
>>> b = a.reshape((5,2))
>>> c = a[::2]
>>> d = a[1::2]
>>> e = a[0:1]
>>> f = a[0:1]
>>> f = f.reshape(())
>>> share_memory(a,b)
80
>>> share_memory(a,c)
40
>>> share_memory(a,d)
40
>>> share_memory(c,d)
0
>>> share_memory(a,e)
8
>>> share_memory(a,f)
8
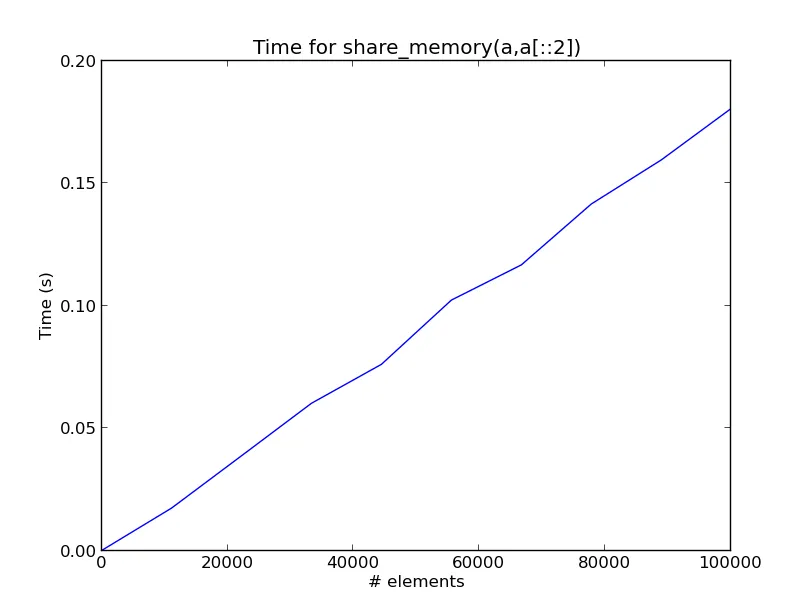
这里展示了在我的电脑上,每次调用 share_memory(a,a[::2]) 所需的时间随着 a 中元素数量的变化而变化的图表。
numpy.may_share_memory的文档(除了内置的help),所以我认为可能还有其他东西--例如numpy.uses_same_memory_exactly。(我的用例比另一个用例略微特殊,因此我认为可能会有更明确的答案)。无论如何,既然在几个numpy邮件列表中看到了您的名字,我猜想答案是“没有这样的函数”。 - mgilsonnumpy.may_share_memory()没有出现在参考手册中,这只是由于参考手册的组织方式不当造成的偶然事件。使用它是正确的选择。不幸的是,目前还没有uses_same_memory_exactly()函数。要实现这样一个函数需要解决一个有界线性丢番图方程,这是一个NP难问题。问题规模通常不会太大,但编写算法很麻烦,所以尚未完成。如果我们完成了,它将被合并到numpy.may_share_memory()中,因此我建议使用它。 - Robert Kernnp.may_share_memory()。 我主要用它来进行调试/优化,以确保我不会意外地分配数组。再次感谢。 - mgilson